이 포스트는 개인적으로 공부한 내용을 정리하고 필요한 분들에게 지식을 공유하기 위해 작성되었습니다. 지적하실 내용이 있다면, 언제든 댓글 또는 메일로 알려주시기를 바랍니다.
💡 2020년, 구글에서 발표한 “Conformer : Convolution-augmented Transformer for Speech Recognition” 논문을 설명한 글이다.
01. 들어가며
기존 end-to-end 자동 음성 인식 접근 방식
acoustic model, pronunciation model, language model 등 수많은 컴포넌트들로 이루어져있었던 과거의 음성 인식 아키텍처는 딥러닝 기술이 도입되면서 end-to-end 방식으로 바뀌어왔다. conformer가 발표되었던 2020년까지도 딥러닝을 활용한 end-to-end ASR에 대한 다양한 접근 방식들이 있었다.
대표적으로 Recurrent Neural Network(RNN)를 활용한 접근 방식이 있었다. RNN은 음향 신호 sequence에 대한 time step 별 의존성(dependency)을 포착하는 데 탁월하기 때문에 많은 연구들이 RNN을 적용하였다.
- RNN 기반의 ASR 선행 연구
한편, 최근 transformer는 self-attention 기법으로 sequence의 거리가 멀어도 맥락 정보들을 잘 파악할 수 있다. 이러한 장점으로 RNN 기반의 NLP 판도를 바꾼 transformer는 컴퓨터비전 뿐만 아니라 end-to-end 음성 인식에도 큰 기여를 했다.
- transformer 기반의 ASR 선행 연구
그리고, Convolution Neural Network(CNN) 역시 레이어마다 receptive field를 통해 지역적인 맥락 정보를 포착하는 데 효과적이므로 end-to-end 음성 인식에서도 성공적으로 사용되어왔다.
- CNN 기반의 ASR 선행 연구
기존 end-to-end 방식의 한계
앞서, 최근의 end-to-end 자동 음성 인식 모델로써 transformer와 CNN이 많이 활용된다고 하였으나, 이 두 모델 모두 근본적으로 한계점이 존재한다. transformer의 경우 긴 길이의 context를 global하게 파악할 수 있는 반면, 지역적인 패턴 정보를 섬세하게 파악하는 데는 강점이 있지 않다. 반면, CNN은 지역적인(local) 패턴 정보를 파악하는 데는 탁월하지만, 지역적인 정보를 활용해서 global 패턴 정보를 파악하기 위해서는 아주 많은 레이어와 그에 따른 파라미터가 필요하다.
따라서 conformer의 저자들은 transformer의 장점과 CNN의 장점을 한 데 모아 그 효과를 극대화 할 수 있도록 자동 음성 인식 모델에 transformer의 self-attention과 convolution 연산을 합쳐서 사용할 것을 제안한다. 즉, conformer란 CONvolution + transFORMER라는 이름에서도 알 수 있듯이 transformer와 CNN의 장점을 합친 모델이다.
02. Conformer 모델
conformer는 conformer encoder와 LSTM decoder로 구성되어 있다. LSTM decoder는 단순히 글자들의 sequence를 출력하기 위한 것이므로, 여기서는 conformer encoder 위주로 살펴보겠다. conformer encoder의 전체적인 아키텍처는 [그림01]과 같다.
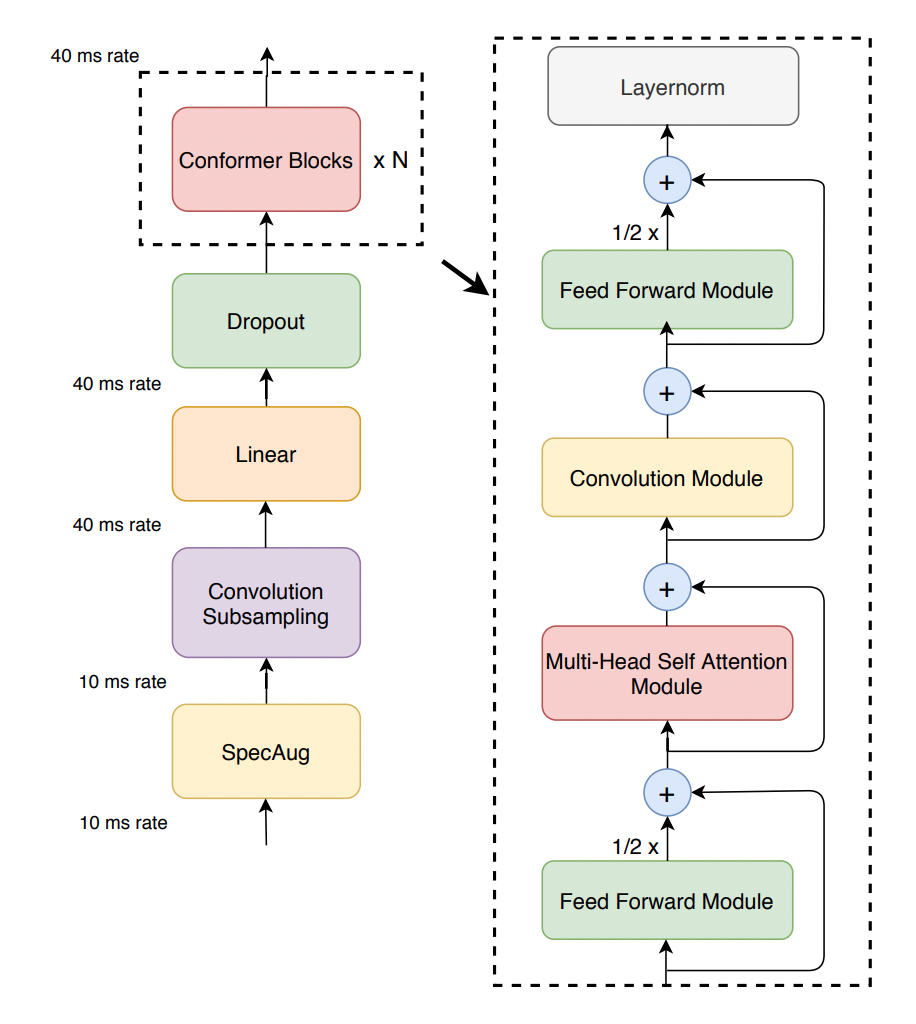 [그림01] conformer의 encoder
[그림01] conformer의 encoder
conformer의 encoder는 ASR 데이터 증강 기법인 SpecAug를 거침으로써 시작된다. 음성 신호는 SpecAug 레이어를 거친 후, Convolution Subsampling 레이어를 통해 특징을 추출하고, Linear 레이어 및 Dropout을 거쳐 Conformer Block을 통과함으로써 encoding된다. 여기서의 핵심은 단연 conformer block이다.
Conformer Block
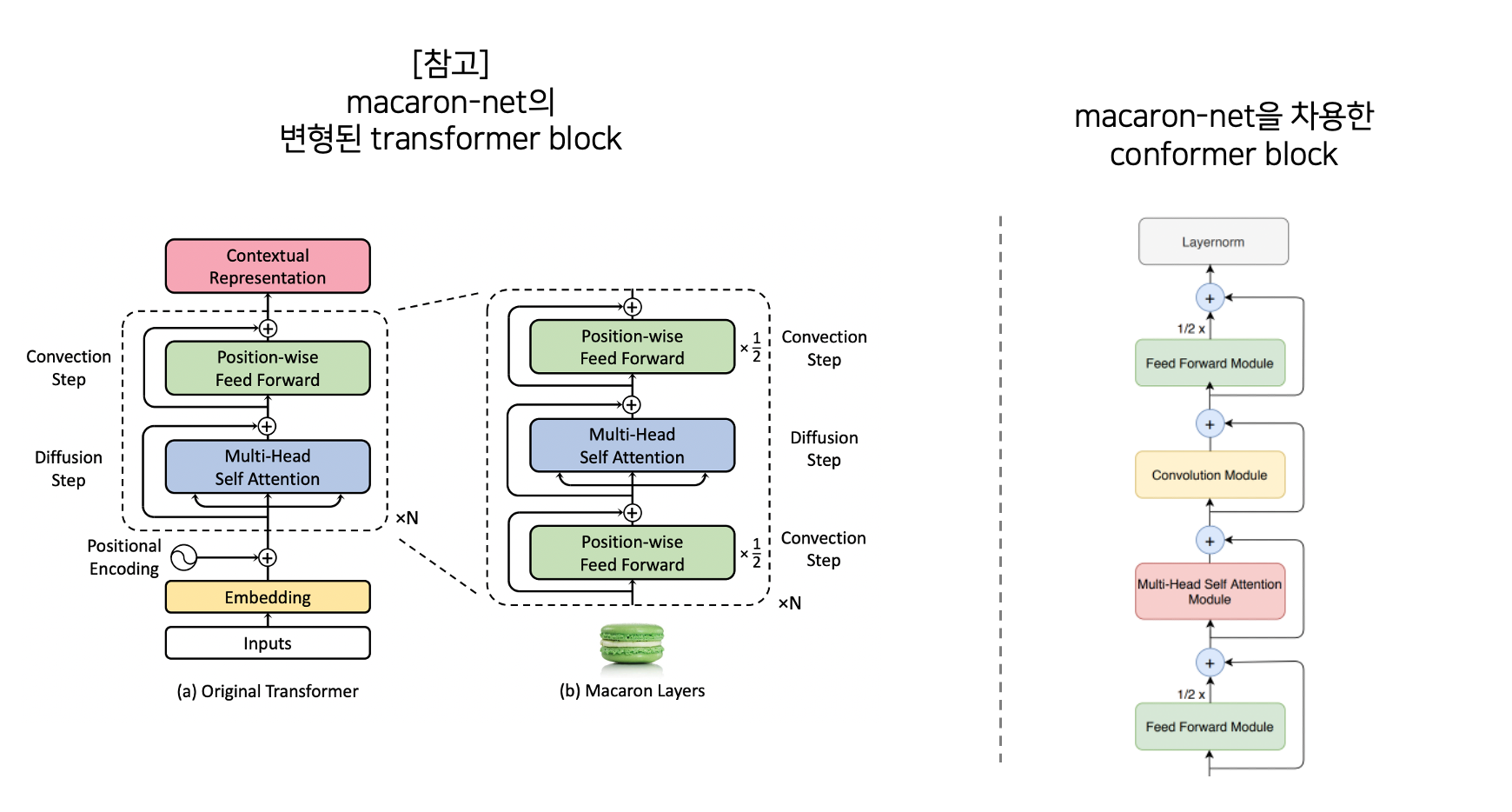 [그림02] transformer block을 변형한 (좌)macaron-net과 (우)conformer block
[그림02] transformer block을 변형한 (좌)macaron-net과 (우)conformer block
conformer block은 macaron-like한 방식으로 transformer 블록을 변형한다. macaron-like 하다라는 말은 transformer를 numerical ODE solver의 관점에서 해석하고자 했던 연구인 [macaron-net](https://arxiv.org/abs/1906.02762) 방식을 차용했음을 의미한다. 이는 기존의 Multi-Head Self Attention(MHSA) → Position-wise Feed Forward(FFN)로 이어지는 transformer block 구조를 마치 마카롱 모양처럼 FFN → MHSA → FFN 방식으로 변경한 것이다. 이때 FFN에서는 half-step residual weights라는 방식으로 독특하게 residual connection을 구성한다. $\tilde{x}_i = x_i + \cfrac{1}{2} \text{FFN}(x_i)$와 같이 residual connection에 1/2만큼의 weight를 주는 방식이다.
macaron-like한 conformer는 FFN → MHSA → Convolution Module → FFN로 이루어져있으며, 아래와 같이 표현할 수 있다.
$\tilde{x}_i = x_i + \cfrac{1}{2} \text{FFN}(x_i)$
$x’_i = \tilde{x}_i + \text{MHSA}(\tilde{x}_i)$
$x’'_i=x’_i + \text{Conv}(x’_i)$
$y_i = \text{Layernorm}(x’'_i + \cfrac{1}{2} \text{FFN}(x’'_i))$
$x_i$는 $i$번째 conformer block의 입력값을 의미하고 $y_i$는 encoding된 출력값을 의미한다. 그럼, macaron-like FFN 사이에 있는 각각의 모듈에 대해서 살펴보도록 하겠다.
Multi-Head Self-Attention(MHSA) Module
 [그림03] conformer의 multi-head self-attention 모듈
[그림03] conformer의 multi-head self-attention 모듈
먼저, MHSA 모듈을 살펴보겠다. 기본적인 transformer의 MHSA와는 달리, Transformer-XL의 relative positional embedding 기법을 적용한 MHSA를 사용하였다.
다음은 Transformer-XL의 relative positional embedding에 대한 설명이다.
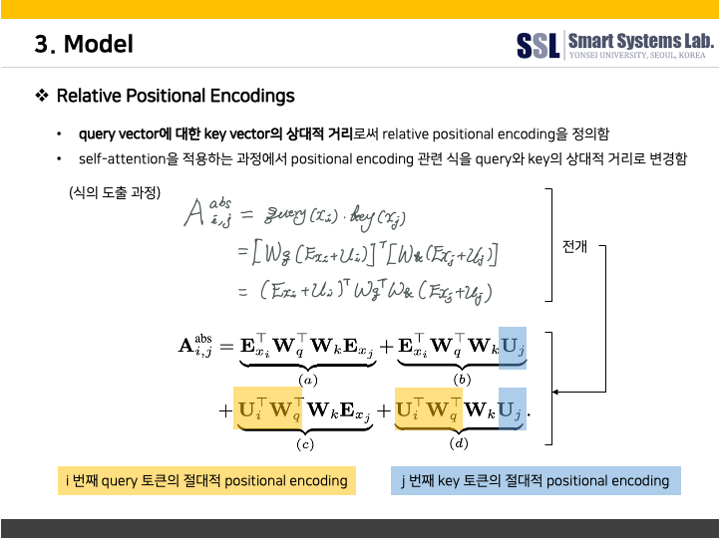
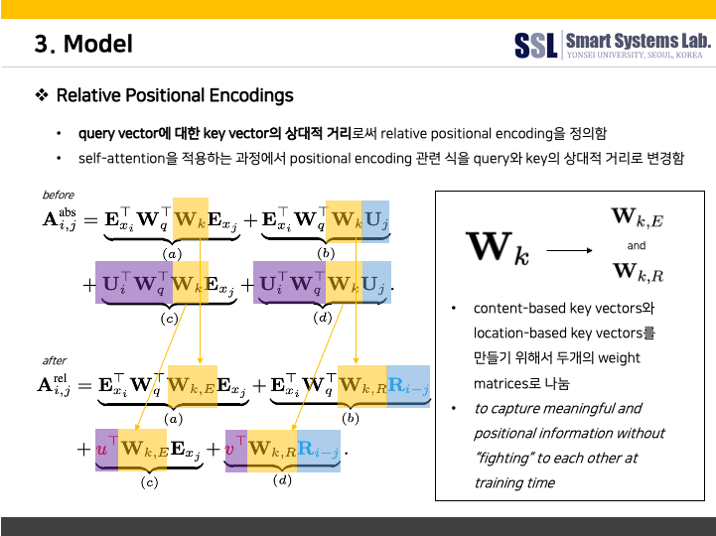
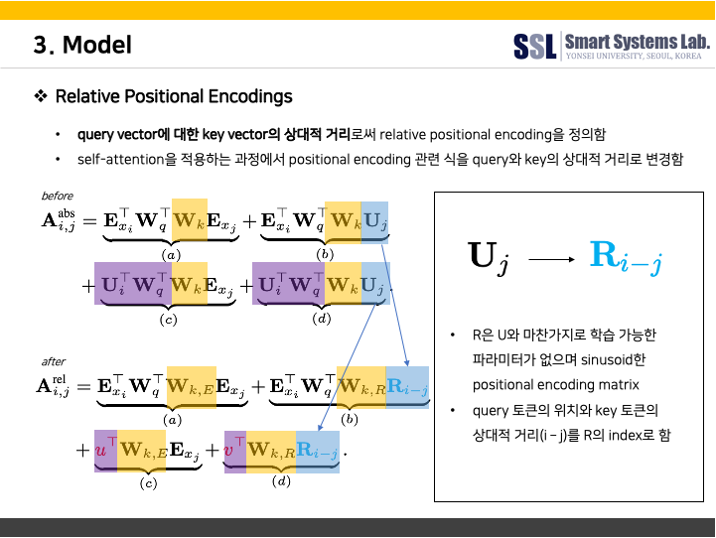
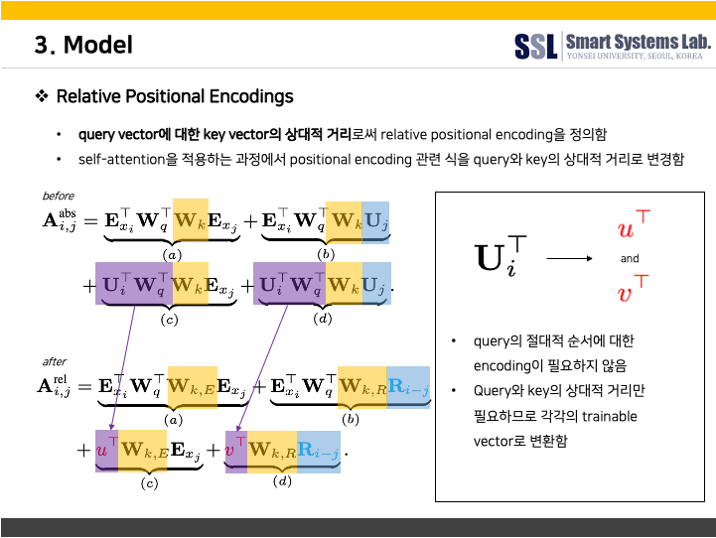
저자들에 따르면, relative positional embedding을 적용하면 self-attention 모듈이 길이가 다른 입력값에 대해서도 잘 generalize 할 수 있기 때문에 발화의 길이가 상이하더라도 강건한 encoder가 될 수 있다고 한다. 이처럼 relative positional embedding을 적용하여 MHSA을 수행되고나면 dropout을 거쳐 residual connection 된 후 다음 단계인 Convolution Module로 넘어가게 된다.
Convolution Module
 [그림04] conformer의 convolution 모듈
[그림04] conformer의 convolution 모듈
MHSA 모듈을 거친 representation은 Convolution Module로 넘어온다. Convolution Module에서는 Conv 연산을 통해서 음성 신호 representation의 지역적인 정보를 학습한다. Convolution Module로 넘어온 음성 신호 representation은 Layernorm을 거쳐 Pointwise Conv → Glu Activation → 1D DepthwiseConv → BatchNorm → Swish Activation → Pointwise Conv → Dropout을 거친다. 그리고 다시금 FFN module로 흘러간다.
Feed Forward Module
 [그림05] conformer의 feed forward 모듈
[그림05] conformer의 feed forward 모듈
FFN 모듈에 대한 세부 사항들은 [그림05]와 같다. 다른 모듈에서와 동일하게 Layernorm은 기본적으로 적용한 후, 2회의 Linear Layer 등을 통과하는 구조다.
03. Experiments
970 시간의 labeled speech dataset인 LibriSpeech를 이용해서 evaluate 하였다. 추가적으로 활용한 언어모델을 학습하기 위해 800M word token text-only corpus를 사용했다고 한다.
decoder는 단순히 한 층을 사용한 LSTM decoder를 사용하였으며, 학습한 언어모델은 shallow fusion 방식으로 활용했다. 참고로 shallow fusion의 개념은 [그림06]과 같다.
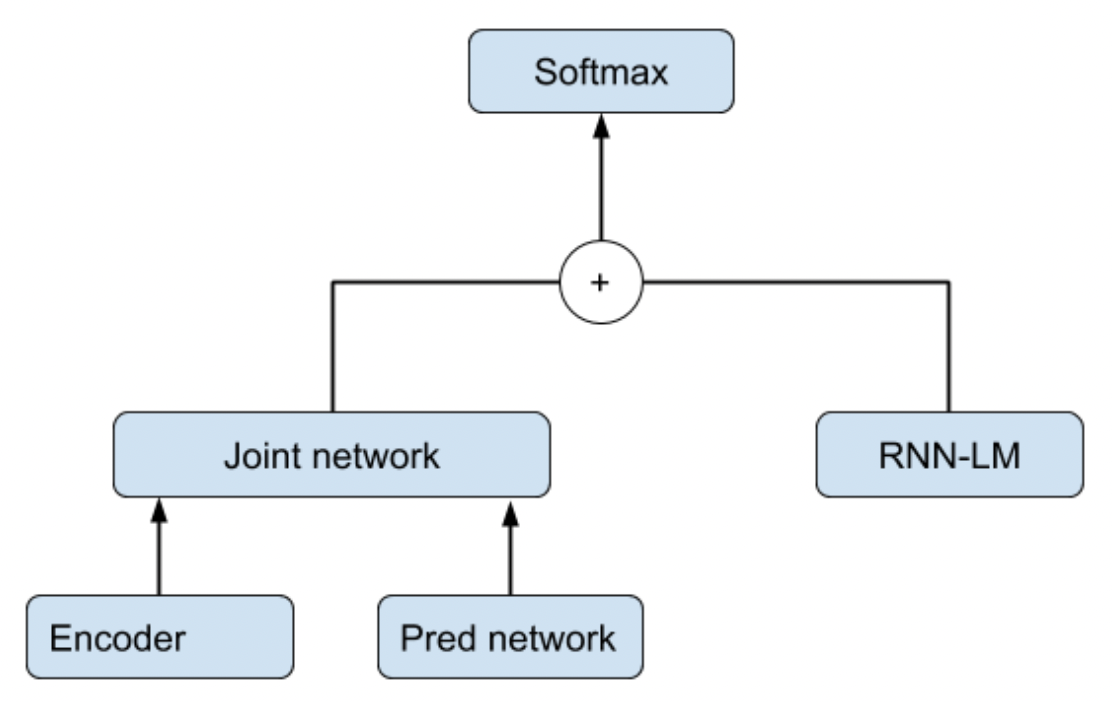 [그림06] shallow fusion 도식
[그림06] shallow fusion 도식
$\mathbf{y}^* = \arg \max_{\mathbf{y}} (\log P_{e2e}(\mathbf{y} | \mathbf{x}) + \lambda \log P_{LM}(\mathbf{y}))$
즉, 음성 신호 sequence $\mathbf{x}$가 주어졌을 때 end-to-end(e2e) 방식으로 글자의 sequence $\mathbf{y}$를 decoding 하는 모델 $P(\mathbf{y} | \mathbf{x})$(여기서는 conformer encoder + LSTM decoder)과 별도로 학습한 언어모델(여기서는 3층짜리 LSTM)을 함께 고려하여 최종 출력될 글자의 확률을 결정하는 기법인 것이다.
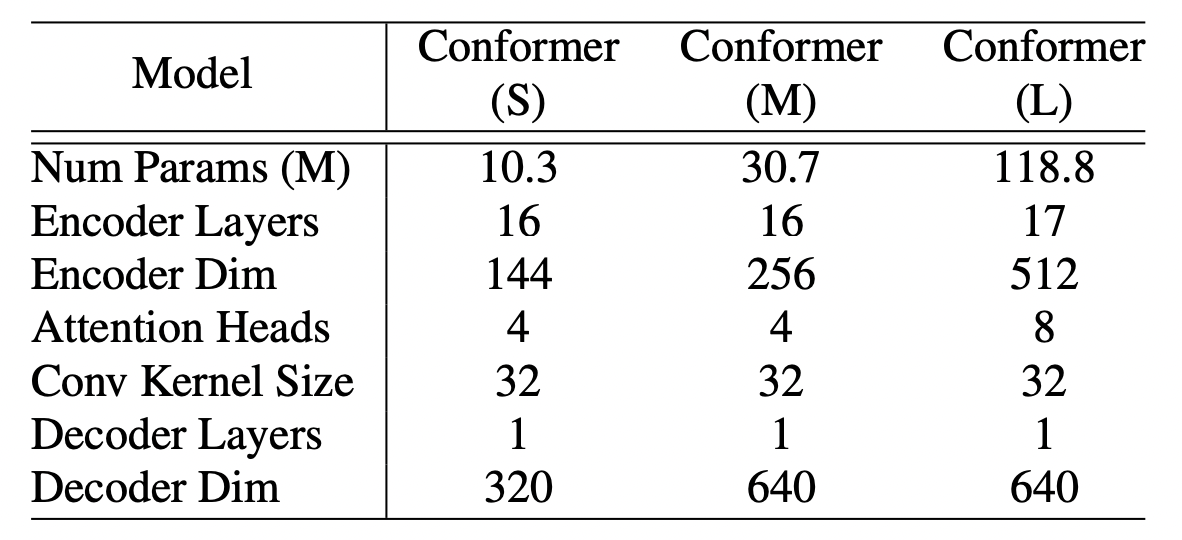 [표01] conformer 모델 크기별 파라미터
[표01] conformer 모델 크기별 파라미터
conformer도 모델의 크기에 따라서 Conformer(S), Conformer(M), Conformer(L)로 구분할 수 있으며, 각각의 파라미터는 [표01]과 같다.
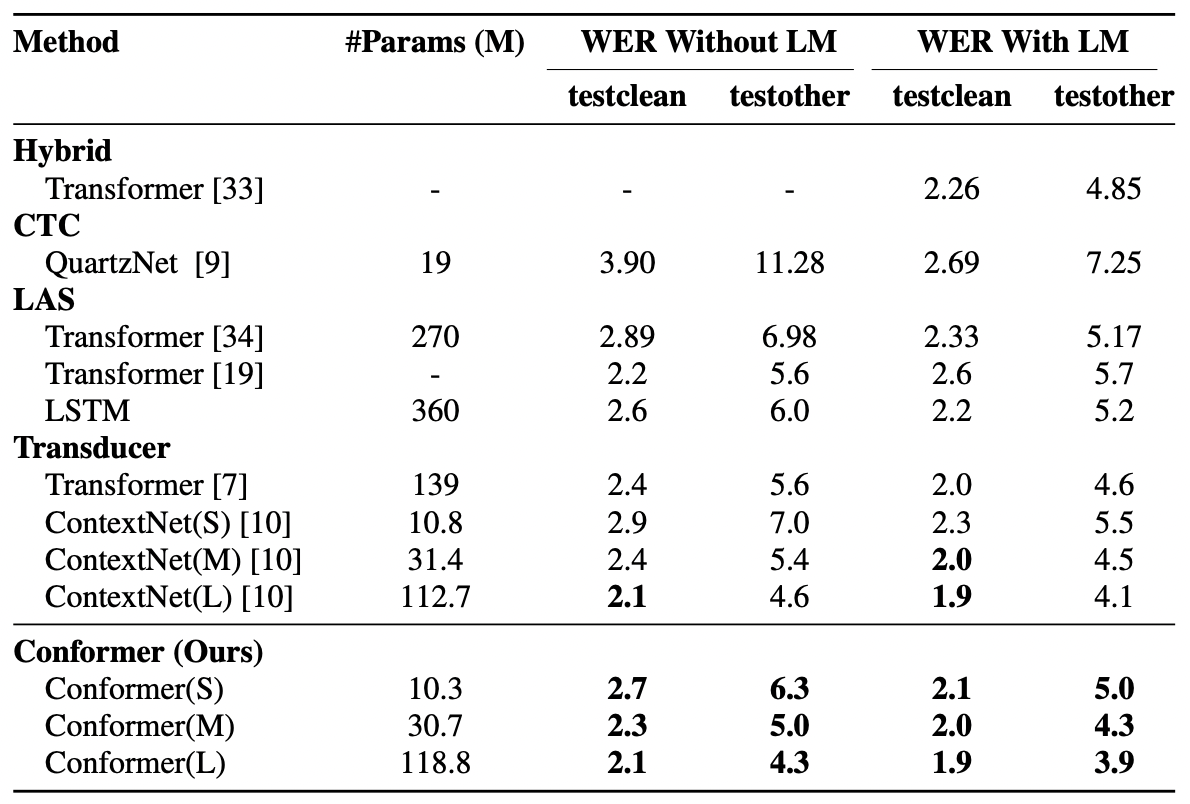 [표02] conformer 모델의 성능 비교표
[표02] conformer 모델의 성능 비교표
[표02]는 confermer가 공개될 당시의 SOTA model이었던 ContextNet, Transformer Transducer 등과 LibriSpeech 데이터셋을 기준으로 Word Error Rate(WER) 성능을 비교한 결과이다. 언어모델을 사용하지 않은 Conformer(M) 모델로도 기존의 Transformer나 LSTM, 또는 CNN을 기반으로 한 모델보다 우월한 성능을 보임을 알 수 있다. 언어모델을 덧붙여 사용한 conformer 모델들은 가장 낮은 WER을 달성하면서 기존의 SOTA 모델을 뛰어넘었다.
04. 정리하며
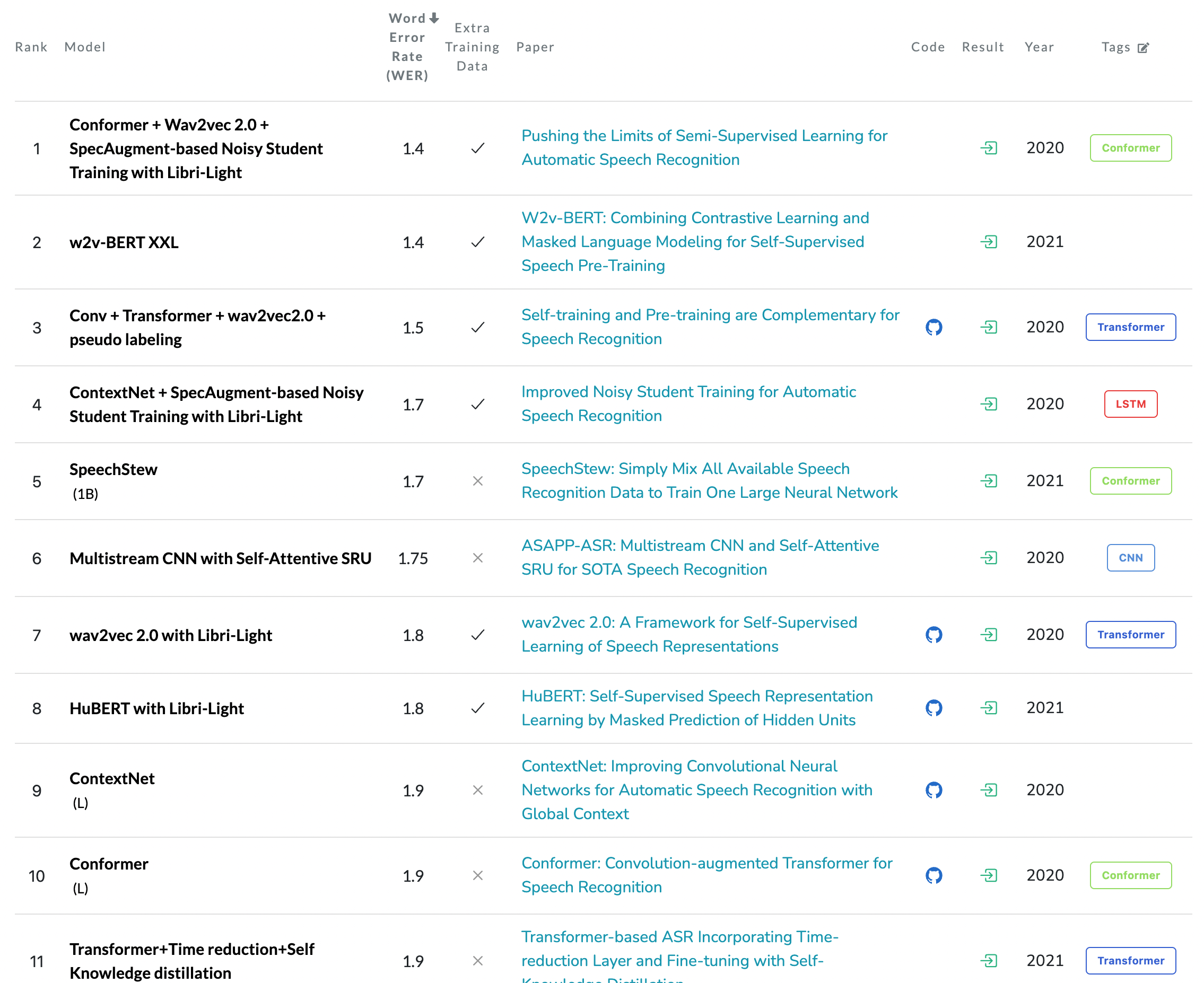 [그림07] 2022년 7월 말 기준 LibriSpeech SOTA 랭킹
[그림07] 2022년 7월 말 기준 LibriSpeech SOTA 랭킹
[그림07]은 현재(2022년 7월 말)를 기준으로 paperswithcode.com에서 발췌한 LibriSpeech test-clean 데이터 기준 음성 인식 SOTA 모델 랭킹이다. 2020년에 제안된 conformer는 그 자체로 아직도 상위 ranking에 있으며, 현재 기준 최고 성능 역시 conformer를 활용한 모델이다. global context를 파악하는 transformer의 장점과 local context를 파악하는 CNN의 장점을 합쳤다는 점이 확실하게 작용한 것 같다.
05. 참고 문헌
[1] 원 논문 : Gulati, Anmol, et al. “Conformer: Convolution-augmented transformer for speech recognition.” arXiv preprint arXiv:2005.08100 (2020).
[2] Macaron-Net : Lu, Yiping, et al. “Understanding and improving transformer from a multi-particle dynamic system point of view.” arXiv preprint arXiv:1906.02762 (2019).
[3] Shallow Fusion : Cabrera, Rodrigo, et al. “Language model fusion for streaming end to end speech recognition.” arXiv preprint arXiv:2104.04487 (2021).