이 포스트는 개인적으로 공부한 내용을 정리하고 필요한 분들에게 지식을 공유하기 위해 작성되었습니다.
지적하실 내용이 있다면, 언제든 댓글 또는 메일로 알려주시기를 바랍니다.
개요
딥러닝 이전의 시대에서 음성 인식은 Hidden Markov Model(HMM)과 Gaussian Mixture Model(GMM)의 혼합형 모델이 주를 이루었다. 그 후, HMM과 딥러닝을 혼합한 모형들도 나오며, 아예 HMM을 사용하지 않는 방식으로 발전하기도 했다. 그래도 음성 인식의 맥락을 이해하기 위해서 HMM과 GMM 기반의 아키텍처를 이해할 필요는 있다.
베이즈 정리로 살펴보는 문제의 정의
음성 인식 모델은 입력 음성 신호 $X(x_1, x_2, …, x_t)$에 대해서 가장 그럴싸한 음소(혹은 단어)의 시퀀스 $W(w_1, w_2, …, w_n)$를 추정하는 문제다. 직관적으로 생각할 때, $X$에 대해서 $W$를 바로 추론하는 방식으로 $P(W|X)$를 최대화하는 모델을 구축하면 좋겠으나, 고전적인 방식으로는 이러한 방식이 불가능했다. 왜냐하면, 같은 단어라도 사람마다 발음도 다르고 높낮이도 다 다르기 때문이다. 따라서 고전적인 방식은 베이즈 정리를 이용하여 이 문제를 우회적으로 푼다.
$ W^* = \arg \max_W P(W|X) = \arg \max_W \cfrac{P(X|W)P(W)}{P(X)} $
베이즈 정리에서 evidence에 해당하는 $P(X)$의 경우, 음소(혹은 단어) 시퀀스 $W$의 모든 경우의 수에 해당하는 음성 신호 $X$의 발생 확률이기 때문에 실제로 구하는 것은 불가능하지만, 다행히 $W$와는 관계가 없는 term 이므로 생략할 수 있다. 따라서 아래와 같은 두 가지 컴포넌트로 구성되는 수식이 도출된다.
$ W^* = \arg \max_W {P(X|W)P(W)} $
우변의 첫째 항 $p(X|W)$은 음향 모델(acoustic model)이라고 하며, 음소(혹은 단어)의 시퀀스가 주어졌을 때 음성 신호 특징 벡터의 시퀀스를 모델링한다. 즉, 음성 신호와 단어 사이의 관계를 표현하는 것이다. 두번째 항인 $p(W)$은 언어 모델(language model)에 해당하며, 단어 시퀀스의 확률을 모델링한다. 즉, 음소(혹은 단어) 시퀀스가 얼마나 확률적으로 자연스러운지를 표현한다.
Automatic Speech Recognition
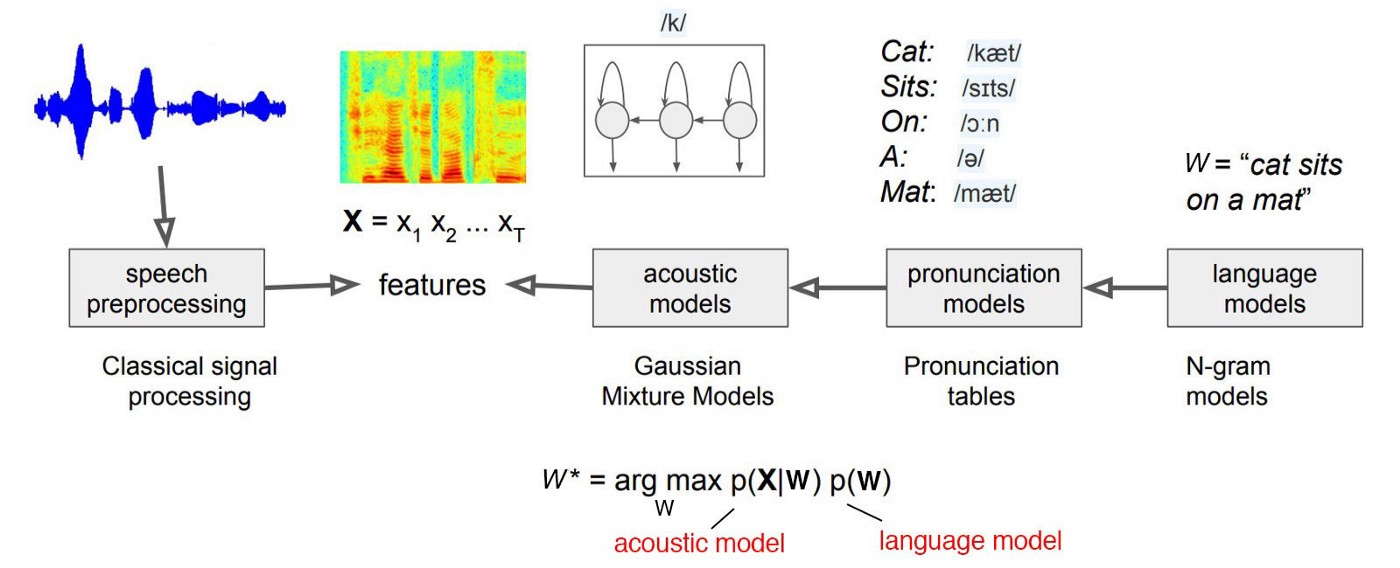
고전적 음성 인식 아키텍처에서는 보통 음향 모델 $p(X|W)$을 GMM으로 모델링한다. 즉, 음소(혹은 단어)의 시퀀스 $W$가 HMM의 hidden state로 주어졌을 때 각 음소(혹은 단어)에서 특정 음성 신호 피처 $X$가 나올 방출 확률을 모델링하는 것이다. 한편, 음소(혹은 단어)들의 시퀀스는 HMM의 전이 확률을 통해 모델링된다.
참고로, 음성 인식을 처음 공부하며 헷갈렸던 점이 있다. HMM은 얼핏 보면 RNN 기반의 언어모델을 펼쳐놓은 것처럼 생겨서(물론 완전히 다른 개념이지만…) 마치 거대한 모델이 하나만 학습되면, 다양한 인풋을 넣었을 때 그에 맞는 아웃풋을 뱉어낼 것만 같다. 그런데 이와는 달리, 고전적인 음성 인식 아키텍처에서는 하나의 HMM이 아닌, 여러 개의 HMM을 학습하여 사용한다. 왜냐하면 하나의 HMM으로는 모든 발화에 대한 성질을 반영하기 힘들기 때문이다. 이를테면, 단어별로 HMM을 학습하여 사용할 수 있다. 즉, 발화에 대한 특징 벡터가 들어오면, 전부 HMM에 투입해보고, 그 중 가장 확률이 높은 HMM에 대한 단어를 예측 값으로 한다.
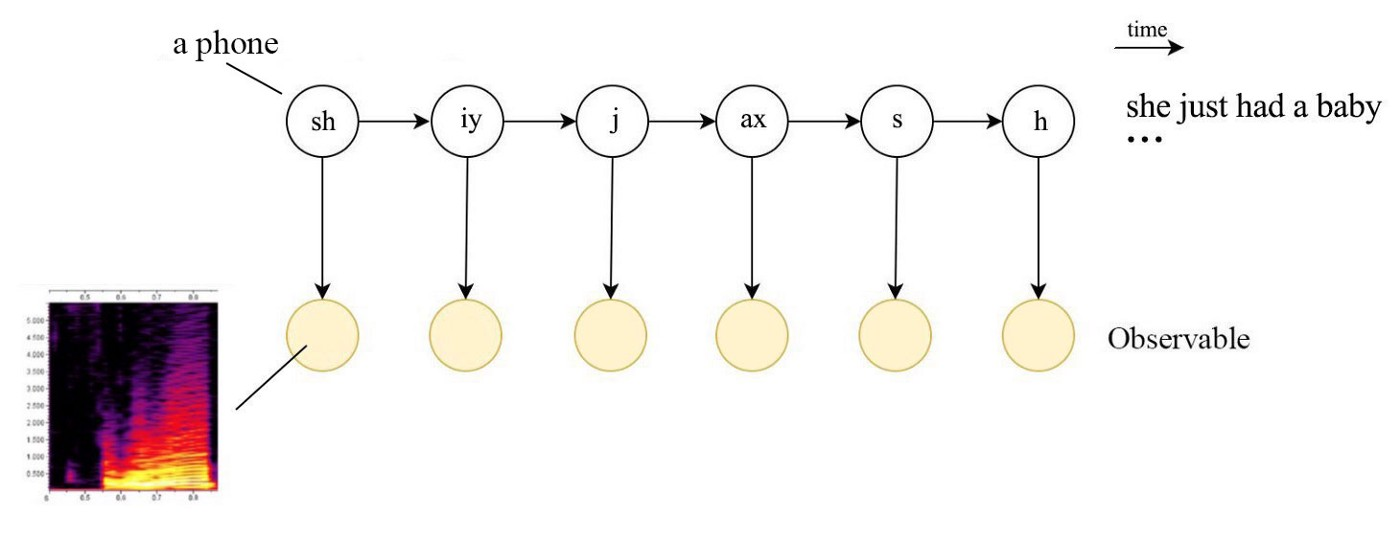
그러나 이러한 방식은 단어의 종류가 엄청 많기 때문에 HMM 또한 매우 많이 필요하므로 scalable하지 않으며, 사용 비율이 낮은 단어는 HMM이 잘 학습되지 않는 문제가 존재한다. 가장 큰 문제로는 새로운 단어는 절대로 인식하지 못하는 문제가 생긴다. 따라서 기본적으로 음소(phoneme)를 단위로 하여 음소마다 HMM을 만들어 사용하는 것이 일반적이다. 이러한 음향 모델의 구조는 위 그림과 같다.
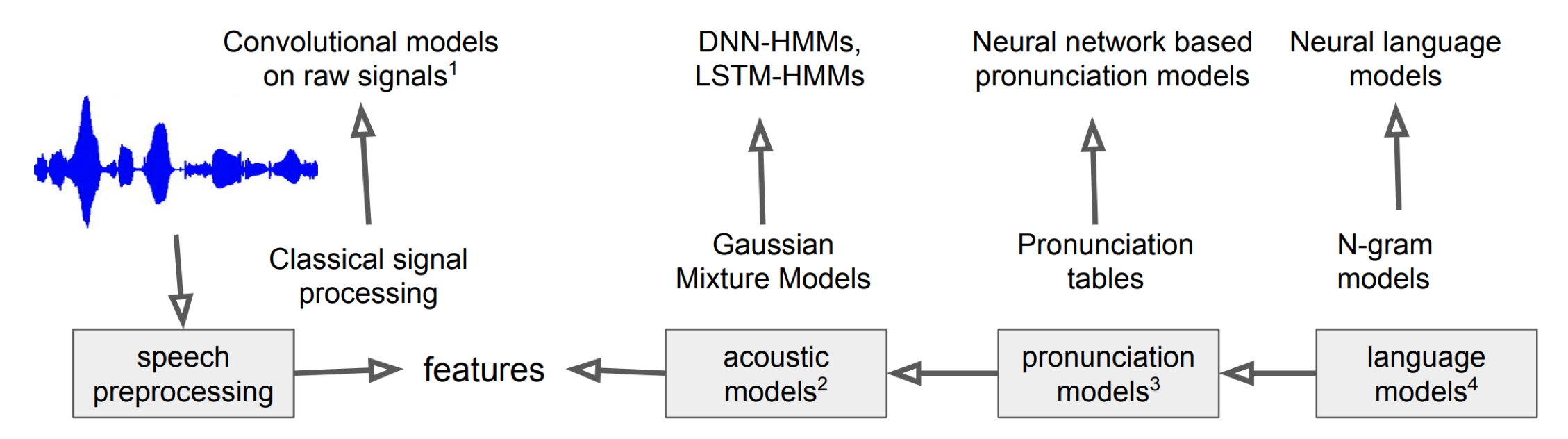
오늘날에는 HMM과 GMM을 활용한 모델링 기법을 잘 사용하지는 않는다고 한다. language model, pronunciation model, acoustic model 등 매우 복잡한 컴포넌트들로 이루어진 고전적인 방식에 딥 러닝 기술이 접목되고 있기 때문이다. 가령 HMM-DNN 구조도 그 예가 될 수 있다. 더 나아가 입력 음성 신호에서 음소(혹은 단어)시퀀스의 확률 $P(W|X)$를 곧바로 추정하는 end-to-end 방식 또한 개발되고 있다.
참고
[1] 고려대 김성범 교수님의 Hidden Markov Model 강의
[2] 고려대 강필성 교수님의 Mixture of Gaussian 강의
[3] ratsgo 님의 블로그
[4] Dongchan’s Blog
[5] Jonathan Hui’s Post