이 포스트는 개인적으로 공부한 내용을 정리하고 필요한 분들에게 지식을 공유하기 위해 작성되었습니다. 지적하실 내용이 있다면, 언제든 댓글 또는 메일로 알려주시기를 바랍니다.
00. 들어가며
음성 인식에서 VQ-Wav2Vec 모델이나, Wav2Vec 2.0 등에서 Vector Quantization 또는 Codebook 등과 같은 용어들이 자주 나온다.
Quantization이라는 용어는 Distillation이나 Pruning 기법과 함께 거대 AI 모델을 경량화 하는 기법으로 흔히 알고는 있다.
그럼에도 Vector Quantization의 정확한 정의가 정리되지 않고서 논문 등을 읽으려니 헷갈리는 점이 많아서 이참에 관련 용어들을 정리하고자 한다.
01. Quantization(양자화)의 사전적 정의
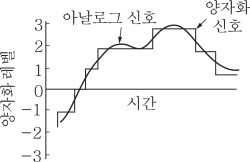 *[그림01] Quantization의 예
*[그림01] Quantization의 예
아날로그양, 즉 단절 없이 연속된 변화량을 일정한 폭 ∆로 불연속적으로 변화하는 유한 개의 레벨로 구분하고, 각 레벨에 대하여 각각 유니크한 값을 부여하는 것. 어떤 특정한 레벨에 속하는 폭 ∆의 범위 내의 모든 아날로그양은 그 레벨에 부여된 특정값으로 대치할 수 있다. 예를 들면, 1.5∼2.5 범위의 모든 아날로그양에는 2라는 값이 주어진다.(전기용어사전)
다시 말해, Quantization의 핵심은 연속된 변화량을 유한개의 레벨로 구분하고, 각 레벨에 대해 특정 값을 부여하는 것이라고 한다.
02. Quantization의 쉬운 예제
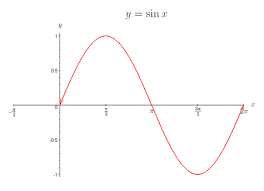 [그림02] 사인 함수
[그림02] 사인 함수
$y = \sin (x)$ 그래프는 [그림02]와 같이 [-1, 1] 사이의 무한한 실수로 표현된다. 컴퓨터는 무한한 실수 데이터를 표현하기 힘들어 2bit로 데이터를 표현해야 한다고 하면, 총 4개의 데이터로 표현할 수 있다. 어떻게 표현해야 4개의 데이터로 $y = \sin (x)$를 표현할 수 있을까?
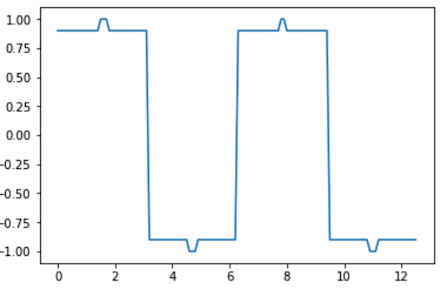 [그림03] 사인 함수를 {1, 0.9, -0.9, -1}로 표현한 경우
[그림03] 사인 함수를 {1, 0.9, -0.9, -1}로 표현한 경우
[그림03]과 같이 {1, 0.9, -0.9, -1} 데이터로 표현할 수 있겠다. 그런데, 이렇게 하면 각 실수값들을 최대한 표현했다고 보기 어렵고, 정보의 손실이 커 보인다.
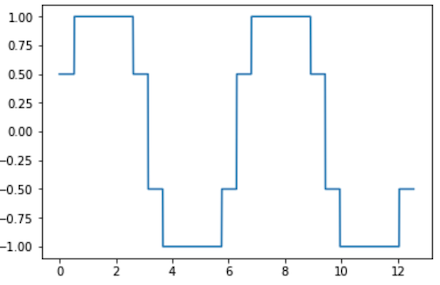
한편, [그림04]와 같이 {1, 0.5, -0.5, -1} 데이터로 표현한다면, 원래의 $y = \sin (x)$ 데이터를 더욱 잘 표현하게 된다. 이 과정은 결국 [-1, 1] 사이의 연속적인 값을 유한한 4개의 레벨로 구분하고, 각 레벨에 대해 {-1, -0.5, 0.5, 1}이라는 대표값을 부여한 것이라고 할 수 있다. 즉, Quantization을 수행한 것이다.
03. Vector Quantization 정리
- 정의 (정보통신기술용어해설)
- 연속적으로 샘플링된 진폭값들을 그룹핑하여, 이 그룹단위를 몇개의 대표값으로 양자화
- 일련의 표본들을 특성화시킨 몇개의 대표값(n-tuple,순서쌍)으로 양자화
- 연속적으로 샘플링된 진폭값들을 그룹핑하여, 이 그룹단위를 몇개의 대표값으로 양자화
- 쉬운 정의
- N개의 특징 벡터 집합 $\mathbf{x}$를 K개의 특징 벡터 집합 $\mathbf{y}$로 mapping 하는 것
- 예를 들어, 특징 벡터 집합이 아래와 같다고 하면,
- $\mathbf{x}$ = {유재석, G-Idle,이정재 ,싸이, 아이유, 마동석, 강호동}
- $\mathbf{y}$ = {가수, 영화배우, 개그맨}
- 양자화 연산자 $f( * )$를 통해서 $\mathbf{y} = f(\mathbf{x})$와 같이 mapping하면 Vector Quantization 결과는 아래와 같음
- 가수 = {G-Idle, 싸이, 아이유}
- 영화배우 = {이정재, 마동석}
- 개그맨 = {유재석, 강호동}
- 이때 $\mathbf{y}$의 각 원소(i.e., 특징)들은
Codeword또는Cluster라고 불리며, $\mathbf{y}$를Codebook이라고 함
따라서, 음성인식에서의 VQ-Wav2Vec이나 Wav2Vec 2.0에서 행해지는 Vector Quantization이란, 학습 가능한 Embedding Matrix를 Codebook으로 사용하여, Encoder를 거친 특징 벡터 $\mathbf{z}$를 Gumbel Softmax 또는 K-means 클러스터링 등으로 Codebook 내 Codeword에 mapping시키는 과정이라고 이해할 수 있겠다.
04. 참고 문헌
[1] 정보통신기술용어해설
[2] DATACREW MAGAZINE
[3] 페이오스 님의 블로그
[4] Machine Learning Glossary