이 포스트는 개인적으로 공부한 내용을 정리하고 필요한 분들에게 지식을 공유하기 위해 작성되었습니다. 지적하실 내용이 있다면, 언제든 댓글 또는 메일로 알려주시기를 바랍니다.
01. Introduction
2018년, 자연어처리 영역의 위대한 한 획을 그은 BERT를 대표로하여, 자연어처리 영역은 대규모의 사전학습 언어모델(large-scale pre-trained langauge models)을 활용한 전이학습(transfer learning) 방식이 주를 이루고 있다. 당연하게도 언어모델이 커질수록 많은 파라미터들을 사용하게 되며, 그에 따라 훌륭한 성능을 달성할 수 있게 된다.
01-1. 거대 언어모델의 맹점
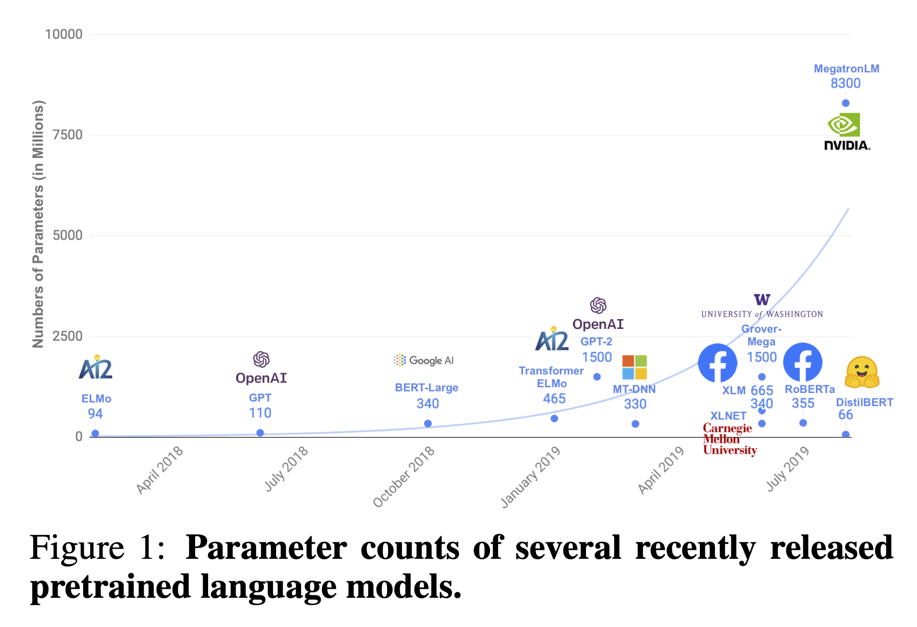 [출처] 원 논문 : DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
[출처] 원 논문 : DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
우선, 주요 언어모델들의 파라미터와 이에 대한 사전학습 비용을 가볍게 살펴보자.
이제는 국민 언어모델이 된 BERT를 먼저 보자. BERT-base는 약 110,000,000(1억 1천만)개의 파라미터를, BERT-large는 약 340,000,000(3억 4천만)개의 파라미터를 가지고 있다. Google research에 따르면, BERT-large를 사전학습 하는 데 16개의 Cloud TPU로 4일이 꼬박 걸렸다고 한다. Cloud TPU v2로 가정했을 때, 16(TPU 수) * 4(학습 일) * 24(시간) * 4.5(시간 당 US$) = $6,912로 계산된다. 즉, BERT-large의 사전학습 비용을 원화로 환산하면 대략 890만 원 정도라고 볼 수 있다.
생성 모델인 GPT-2는 어떨까? GPT-2는 약 1,500,000,000(15억)개의 파라미터를 가지고 있다. The Register에 따르면, GPT-2의 학습에는 시간 당 $256 만큼 소요되는 256개의 Google Cloud TPU v3 cores를 사용했다고 한다. $256를 어림 잡아 원화 33만 원으로 계산한다고 했을 때, 하루에 792만 원 가량으로 계산되는데, 놀라운 점은 GPT-2를 개발한 OpenAI는 사전학습에 소요된 시간을 공개하지조차도 않았다.
이후 나온 GPT-3와 현재 화두가 되고 있는 ChatGPT의 경우, 175,000,000,000(1750억)개의 파라미터를 가지고 있다. 앞서 살펴본 모델과 단순 비교만 하더라도 실로 엄청난 규모이다. 참고로 GPT-3를 학습하는 데 약 1200만 달러, 즉, 150억 원 정도가 소요되었다.
01-2. DistilBERT의 등장 배경
위와 같이 DistilBERT의 등장 이후에도 여전히 언어모델은 일반 기업들은 손대지도 못 할 정도의 초거대 모델로 개발되고 있다. 지금도 여전한 문제이기도 한 언어모델의 거대화는 DistilBERT의 등장 배경이기도 하다. 이와 함께 논문에서 언급한 내용들은 아래와 같다.
- 거대 언어모델을 학습하기 위한 연산에는 상당한 carbon footprint, 즉, 환경 비용(environmental cost)이 소요됨
- 거대 언어모델의 연산과 메모리 소요 등을 고려했을 때, 디바이스 상에서 실시간으로 사용되기 어려움
따라서 본 논문은 지식 증류(knowledge distillation) 기법을 활용하여 거대 언어모델인 BERT(오늘날에는 BERT를 거대 모델로 치지 않겠지만…)를 경량화 하는 방식을 제시한다.
02. 지식 증류 (Knowledge Distillation)
지식 증류(knowledge distillation)란, 이미 사전학습 되어있는 대규모 모델인 teacher로부터 경량화된 압축 모델인 student로 AI의 지식을 나누어 주는 개념이다. 증류(distillation)라는 단어가 액체 혼합물을 가열하여 액체 혼합물을 분리하는 과정을 의미한다는 점을 생각하면 그 뜻이 쉽게 와닿는다.
사실 지식 증류에도 다양한 방식이 있겠으나, 본 논문에서는 Geoffrey Hinton의 Softmax Temperature를 이용하였다.
02-1. Softmax Temperature
기본 Softmax의 한계
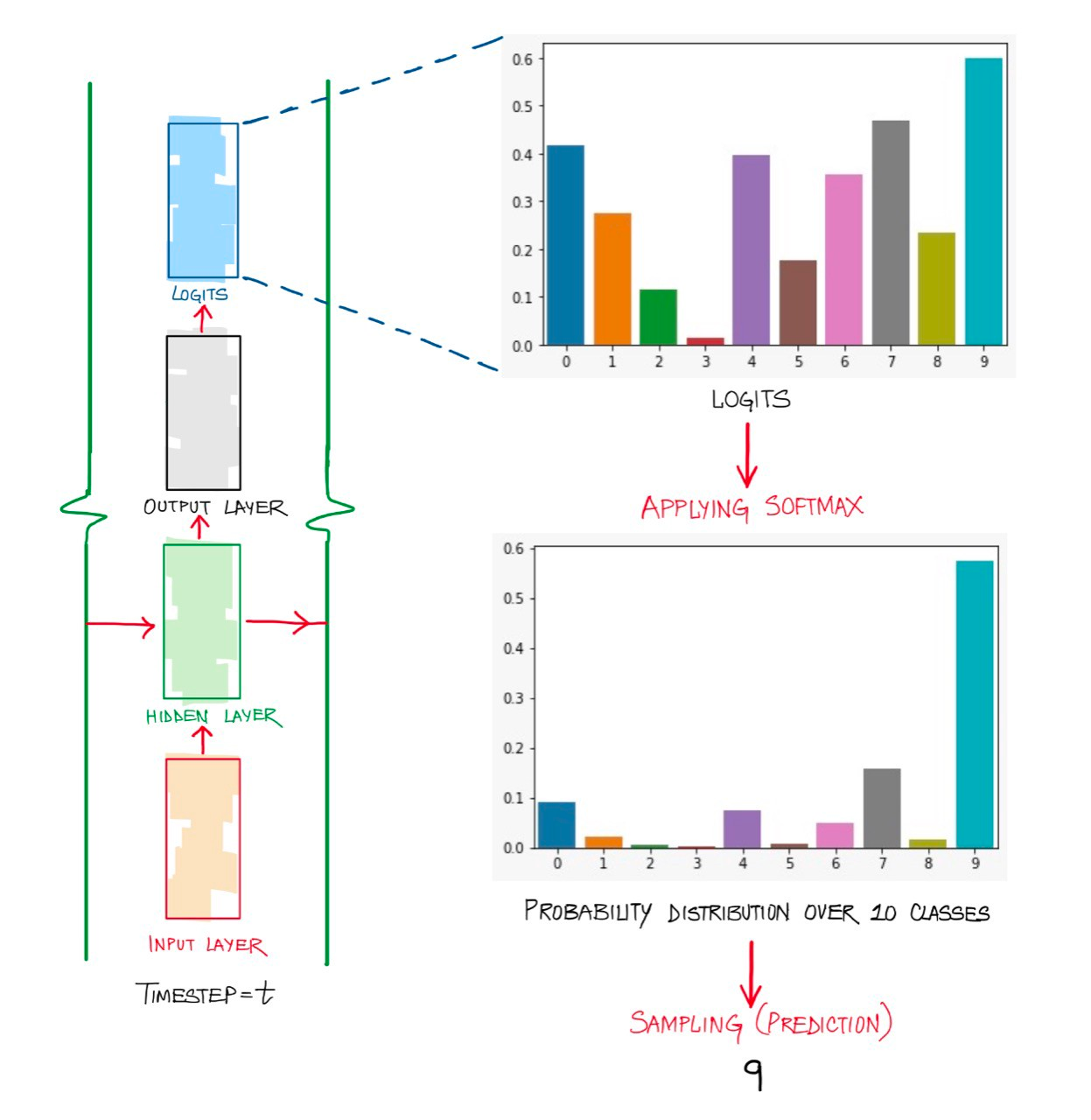 [출처] : Softmax Temperature and Prediction Diversity
[출처] : Softmax Temperature and Prediction Diversity
일반적인 지도학습의 분류 모델은 모델의 예측 결과(logit)에 softmax를 취한 분포와 원 핫 인코딩 된 정답의 분포 간의 크로스 엔트로피 로스를 최소화 한다. 이에 따라 잘 학습된 모델은 정답 클래스에 대해서는 높은 확률로 분류해 낼 것이고, 오답 클래스에 대해서는 0에 가까운 값(near-zero)을 보일 것이다.
하지만, 같은 non-zero의 오답 클래스라 하더라도 어떤 클래스는 조금이나마 더 정답 클래스와 유사할 것이다. 극단적인 예를 들면, 바둑이를 분류하는 태스크에서 멍멍이라는 오답이 스파게티라는 오답보다 더 강아지와 유사하지 않은가? 여기서 ‘멍멍이’와 같은 지식을 암흑 지식(dark knowledge)라고 한다. softmax로 잘 학습된 분류기는 바둑이에 대해서는 0.99에 가까운 확률로 정답으로 분류를 하고, 멍멍이에 대해서는 0.000…1에 가까운 확률로 오답으로 분류할 것이다. 무언가 완벽해보이지 않는다. 즉, 단순한 softmax는 엔트로피가 낮다!
Softmax에 랜덤성을 더한 Temperature Scaling
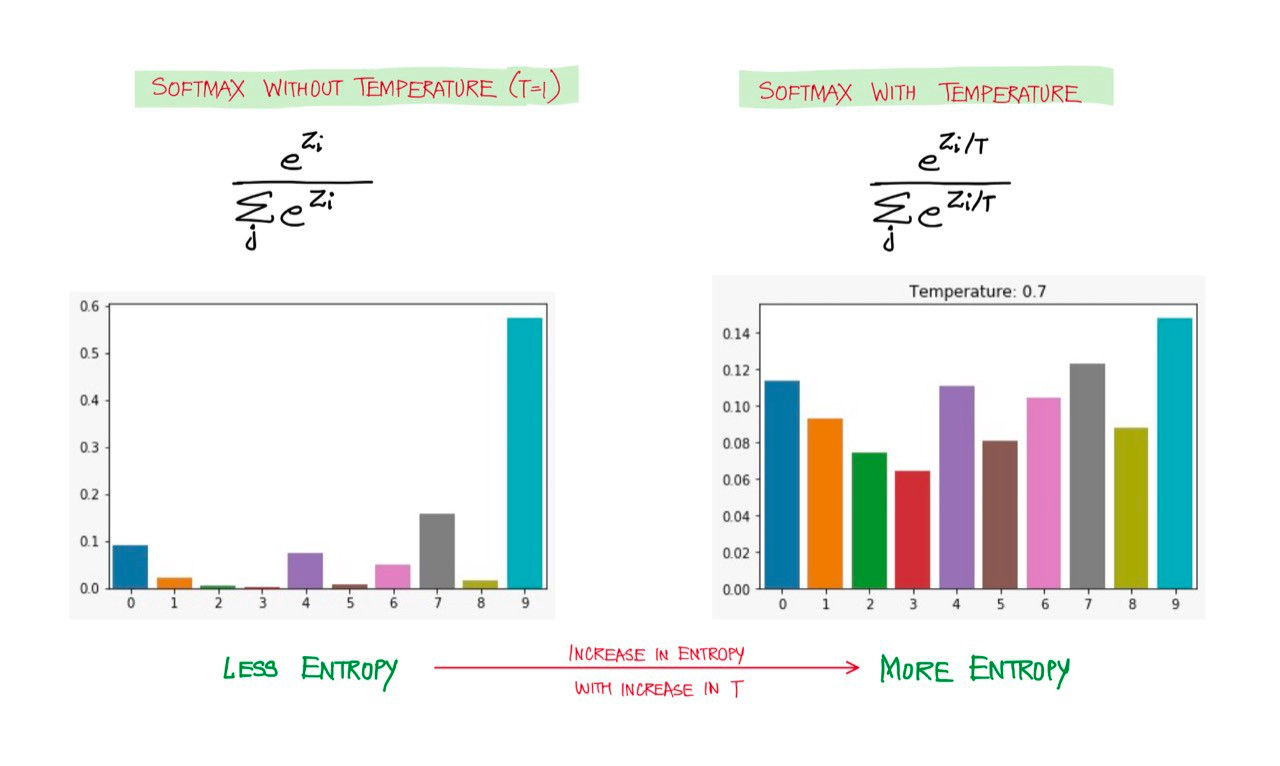 [출처] : Softmax Temperature and Prediction Diversity
[출처] : Softmax Temperature and Prediction Diversity
위와 같은 softmax 함수의 한계에 대한 해결 방법이 바로 temperature scaling으로, 모델의 예측 결과인 logit 벡터를 temperature 값 $T$만큼 나누어주는 softmax 방식이다.
이를 수식으로 표현하면 $\cfrac{\exp{(z_i / T)}}{\sum_j \exp{(z_j / T)}}$와 같다. 즉, temperature $T=1$ 일 경우 softmax와 같아지는 구조이며, temperature $T \to \infty$ 일 경우 uniform distribution을 가진다. 일반적으로 $T$는 1~20 정도의 값을 사용한다고 한다.
이처럼 학습 시 temperature scaling을 적용한 확률을 soft target probability라고 한다. 학습을 마친 후 추론 시에는 scaling을 하지 않고, $T=1$인 기본 softmax를 사용한다. 이러한 방식은 generalization에 효과적이어서 테스트 데이터셋에 대해 더욱 좋은 성능을 보인다고 알려져 있다.
02-2. Training Loss
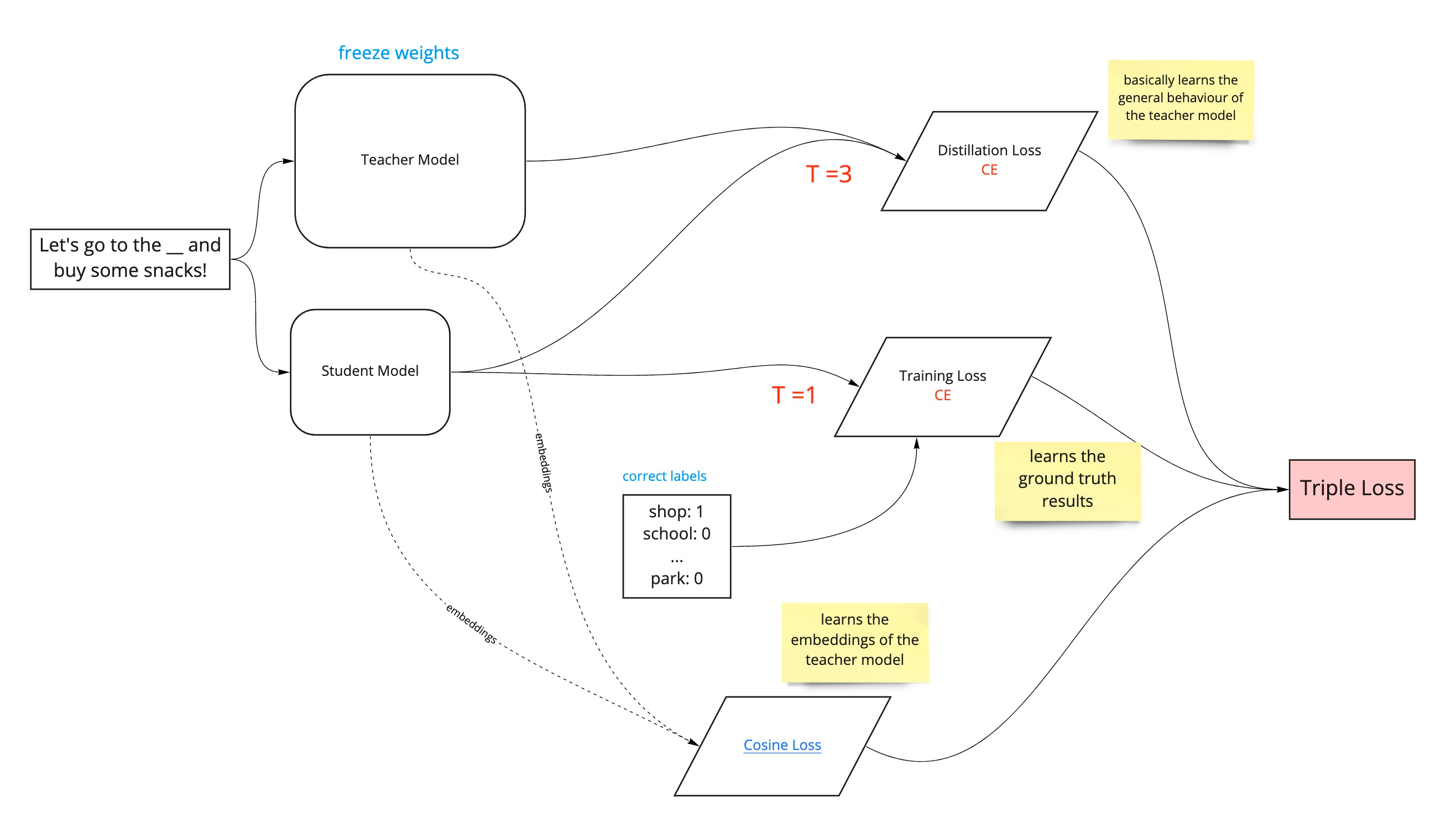 [출처] : Knowledge Distillation of Language Models
[출처] : Knowledge Distillation of Language Models
DistilBERT를 학습하기 위해서는 Teacher - Student Cross Entropy (Distillation Loss), Student Masked Language Modeling Loss (MLM Loss), 그리고 Teacher - Student Cosine Embedding Loss을 활용하여 학습한다. 우선, downstream 태스크가 아니므로, [MASK]를 예측하는 학습을 수행하는 점을 염두에 두자.
Loss 1 : Teacher - Student Cross Entropy (Distillation Loss)
먼저, 사전학습 된 teacher의 logit에 대해 temperature scaling이 적용된 softmax를 취하여 [MASK]에 대한 soft target label로 삼는다. 이후 사전학습을 진행할 student의 logit에 대해서도 temperature scaling이 적용된 softmax를 취하여 나온 [MASK]에 대한 예측값을 구하고, 예측값과 soft target label 간의 크로스 엔트로피 로스를 구한다. 이를 distillation loss라 한다. 즉, student 모델이 teacher 모델이 가지고 있는 지식을 전수받는 과정이다.
수식으로 $L_{ce} = \sum_{i} t_{i} * \log(s_{i})$로 표현할 수 있으며, $t_i$는 teacher의 확률이며 $s_i$는 student의 확률이다.
Loss 2 : Student Masked Language Modeling Loss (MLM Loss)
사전학습을 진행할 student 모델에 대해 일반적인 BERT의 Masked Language Modeling(MLM) loss $L_{mlm}$을 적용한다. MLM loss에 대해서는 temperature scaling을 적용하지 않은 기본적인 softmax를 이용한, hard target, hard prediction을 활용한다. 이를 student loss라고도 부른다.
Loss 3 : Teacher - Student Cosine Embedding Loss
저자들은 student 모델이 더욱 teacher 모델과 닮아질 수 있도록 코사인 유사도를 활용하기까지 했다. 단순히 입력 벡터 $x$가 정답 벡터 $y$와 같게 학습하는 지도학습 방식을 넘어, teacher 모델의 hidden 벡터와 student 모델의 hidden 벡터가 일치(align)되도록 학습하는 것이다.
수식으로 $L_{cos} = 1- \cos (T(x), S(x))$로 표현할 수 있으며, $x$는 입력 벡터, $T$와 $S$는 각각 teacher 모델 및 student 모델을 의미한다.
(위 그림에 따르면, teacher 모델과 student 모델의 출력값인 $T(x)$와 $S(x)$로 cosine loss를 구하지 않고, 각 모델의 단어 임베딩을 직접 활용하여 cosine loss를 구한다. 두 방식 중 어떤 방식을 활용했는지에 대한 구체적인 설명이 논문에 명시되어 있지는 않은 듯 하다.)
Triple Loss = Loss 1 + Loss 2 + Loss 3
결과적으로 최종적인 triple loss는 $L = \alpha * L_{ce} + \beta * L_{MLM} + \gamma * L_{cos}$이며, 이때 $\alpha + \beta + \gamma = 1$이다.
03. DistilBERT의 디테일
03-1. Student Model의 구조
Next Sentence Prediction(NSP) 태스크를 수행하지 않음
DistilBERT의 student 모델은 기본적으로 BERT와 동일하나, 다음과 같은 차이가 있다.
token-type embedding의 제거- token-type embedding이란, transformers 라이브러리의
token_type_ids에 대응되며, BERT에서[SEP]토큰으로 두 문장 간 관계를 학습할 때 각 문장을 구분함
- token-type embedding이란, transformers 라이브러리의
pooler의 제거- pooler란, BERT에서 얻은 contextual embedding 중
[CLS]토큰의 임베딩에 해당됨
- pooler란, BERT에서 얻은 contextual embedding 중
이러한 차이는 기존 BERT가 사전학습 할 때 수행하는 Next Sentence Prediction(NSP) 태스크를 수행하지 않음을 의미한다.
teacher BERT를 활용한 초기화
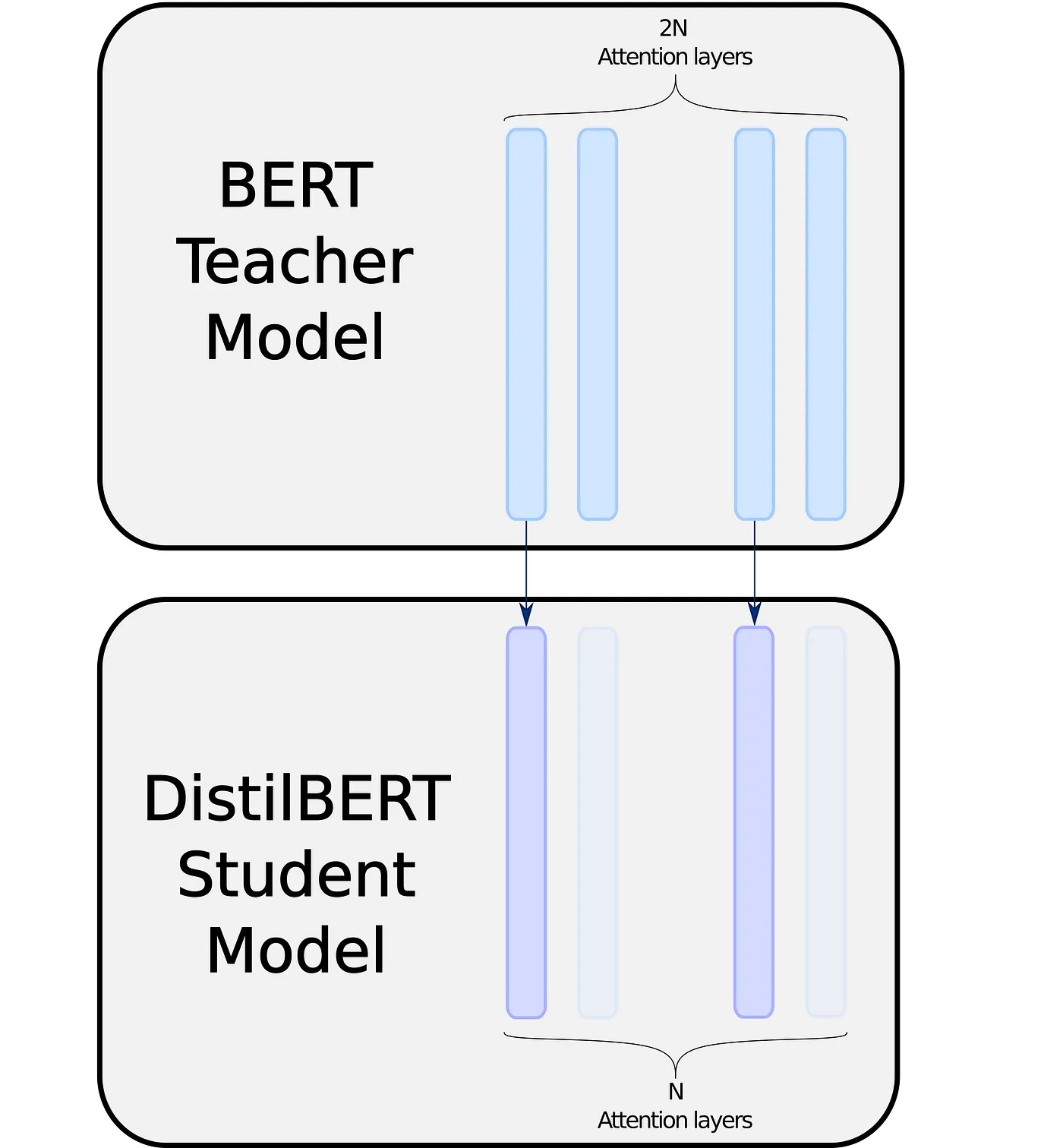 [출처] : Distillation of BERT-Like Models: The Theory
[출처] : Distillation of BERT-Like Models: The Theory
또한 위 그림과 같이 teacher 모델의 레이어의 절반만을 복사하여 초기화함으로써 레이어의 수를 절반으로 감소시켰다.
03-2. 기타 학습 세부 사항
DistilBERT는 아주 큰 배치 사이즈(배치당 4K의 데이터)를 활용하여 학습하였다. NSP 태스크를 수행하지 않았으며, RoBERTa의 트릭인 dynamic masking 기법을 사용하였다. dynamic masking은 입력을 만들 때 마다 masking을 다시 하는 기법이다.
데이터와 컴퓨트 파워
BERT와 동일한 데이터인 English Wikipedia와 Toronto Book Corpus를 활용했다. DistilBERT 학습은 16GB V100 GPU 8대로 90시간이 소요되었다. 참고로 RoBERTa의 경우 32GB V100 GPU 1024대로 하루가 걸렸다는 점을 고려하면 대단한 수치다.
04. 결과 및 결론
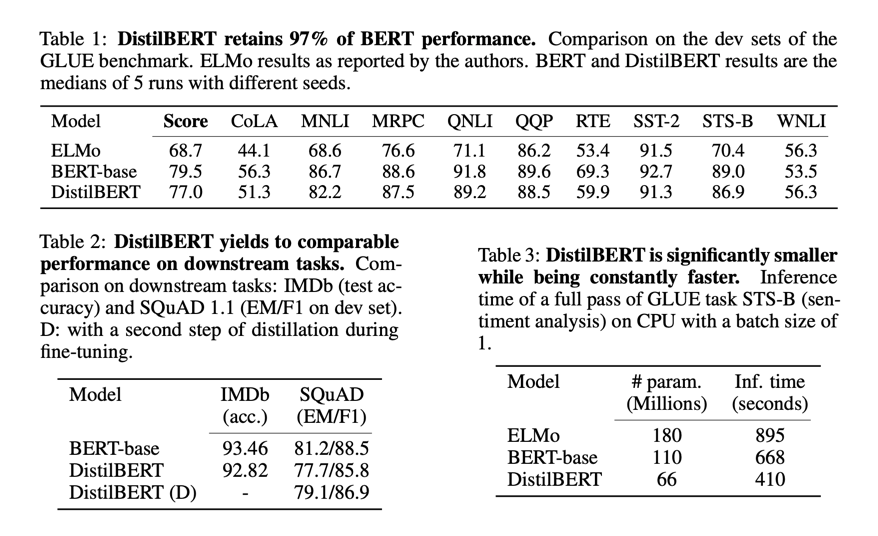
distilBERT는 distillation 기법으로 빠르게 학습하였음에도 불구하고, 기존 BERT에 비해 40%나 가벼워졌고 60%나 빨라졌으며 97% 성능을 유지했다!
05. 참고 문헌
[1] 원 논문 : DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
[2] 블로그 : The Staggering Cost of Training SOTA AI Models
[3] Harshit Sharma의 포스트 : Softmax Temperature and Prediction Diversity
[4] kaggle : 📢NLPStarter4📄🤗DistilBert,Bert(Base-Cased)🤗:)
[5] Alex Nim의 포스트 : Knowledge Distillation of Language Models
[6] Remi Ouazan Reboul의 포스트 : Distillation of BERT-Like Models: The Theory