이 포스트는 개인적으로 공부한 내용을 정리하고 필요한 분들에게 지식을 공유하기 위해 작성되었습니다. 지적하실 내용이 있다면, 언제든 댓글 또는 메일로 알려주시기를 바랍니다.
01. 요약
RoBERTa는 Robustly Optimized BERT approach의 약자이다. ELMo, GPT, BERT, XLM, XLNet 등 self-training 방식인 기존 언어 모델들은 기존 모델들에 비해 비약적인 성능 향상을 보였다. 하지만, 이처럼 다양한 방식의 모델들이 존재함에도 불구하고, 모델 관점에서 무엇이 성능을 극대화하는 요인인지 알기 어려웠다.
Facebook AI의 RoBERTa 저자들은 BERT의 사전학습 방식이 상당히 undertrained 되어 있다고 주장하며, BERT 이후 나온 post-BERT 방식을 능가하는 새로운 사전학습 방식으로 RoBERTa를 제안했다. BERT의 사전학습에는 상당한 하드웨어 자원과 학습 시간이 필요하여, 다방면에서 실험을 진행해보는 데 한계가 있을 수 있다. 그럼에도 불구하고 RoBERTa의 저자들은 모델 관점에서 BERT의 디자인을 다양하게 변형 및 실험해보았다는 기여를 했다. 이러한 시도의 결과로, 저자들은 RoBERTa를 통해 undertrained 되어 있는 BERT를 더욱 강건하게 최적화 할 수 있는 방법을 제시했다.
02. RoBERTa의 특징
RoBERTa는 BERT와 유사하지만, 다음과 같은 특징이 있다.
- 특징1 : 더욱
많은 데이터를 사용하여, 더욱큰 batch로, 더욱오래모델을 학습하였다. - 특징2 : BERT의 사전학습 방식에서
Next Sentence Prediction(NSP)태스크를 제거하였다. - 특징3 : 더욱
긴 sequence로 학습하였다. - 특징4 : 사전학습 데이터에 더욱
동적 마스킹 방식을 적용하였다.
특징1 - 더욱 많은 데이터, 더욱 큰 batch, 더욱 오래 학습
더욱 많은 데이터
BERT처럼 대규모 코퍼스로 사전학습하는 방식의 언어 모델은 학습 데이터의 크기가 매우 중요하다. (Baevski et al. 2019)에 따르면, 데이터의 규모를 키우는 것이 end-task의 성능 향상에 도움이 된다고 한다. RoBERTa 이전에도 original BERT보다 더욱 많은 데이터를 사용했던 시도들은 있었으나, 해당 데이터들이 공개되어 있지는 않았다. 따라서 RoBERTa 저자들은 최대한 많은 학습 데이터를 활용해서 언어 모델을 학습해보고자 했다. 사용한 데이터는 아래와 같다.
- BOOK CORPUS와 영어 WIKIPEDIA
- original BERT를 학습하기 위해서 사용되었던 16GB의 데이터다.
- CC-NEWS
RoBERTa에서 추가됨- 저자들이 수집한 2016년 9월 ~ 2019년 2월 동안의 뉴스 데이터로, 6,300 만 개의 크롤링된 영어 뉴스 기사로 구성되었으며, 76GB에 달한다.
- OPEN WEB TEXT
RoBERTa에서 추가됨- 최소 3개의 좋아요를 받은 Reddit으로부터 추출된 텍스트 데이터로, 38GB에 달한다.
- STORIES
RoBERTa에서 추가됨- CommonCrawl 데이터의 일부로, 31GB에 달한다.
더욱 큰 batch
(Ott et al., 2018)에 따르면, 기계번역 모델은 큰 미니배치 사이즈를 이용할 때 더욱 빠르게 수렴되고 좋은 성능을 낼 수 있다. (You et al., 2019)는 이러한 방식이 BERT에도 적용된다고 주장한다. 이에 RoBERTa 저자들은 더욱 큰 배치 사이즈를 적용해보았다.
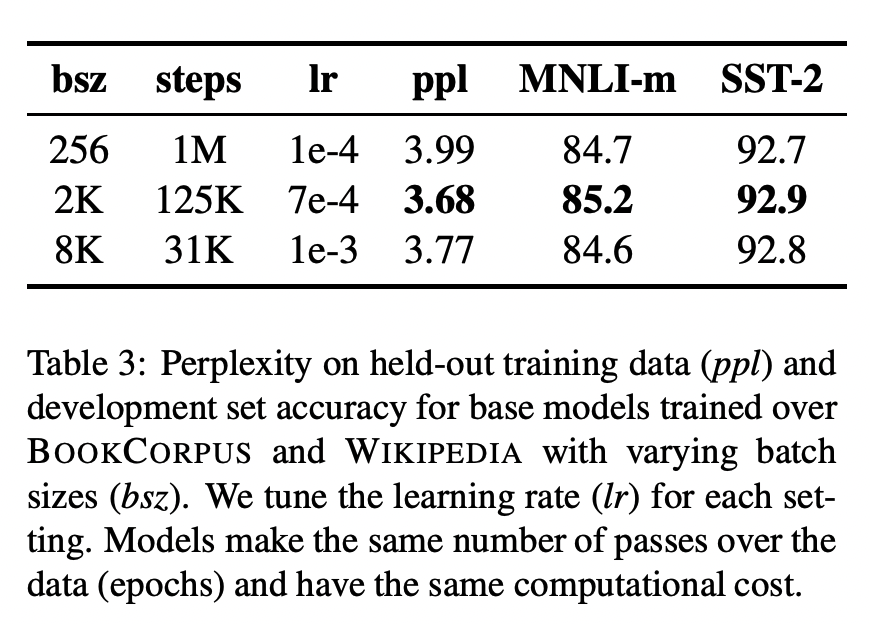
위와 같이 배치 사이즈(bsz)와 스텝(steps)의 곱이 유사하도록 환경을 구성함으로써 계산 복잡도를 유사하게 맞추어 놓은 후 비교했을 때, 배치 사이즈가 커질 때 perplexity(PPL)과 end-task의 정확도 모두 증가할 수 있음을 확인했다.
더욱 오래 학습
RoBERTa의 저자들은 더욱 오랜 스텝 동안 사전학습 하는 것이 궁극적으로 더 나은 성능을 보이는지를 실험하였다.
특징2 - Next Sentence Prediction 태스크 제거
original BERT는 사전학습 시 두 개의 문장 segment를 입력하는데, 50%는 같은 문서에서 인접한 문장들을, 50%는 다른 문서에서 각각 추출한 문장들을 사용하여 두 문장이 인접한 문장인지를 학습한다. 이를 Next Sentence Prediction(NSP) 태스크라고 하며, NSP loss로 구현된다.
original BERT가 이러한 방식으로 학습하는 이유는 BERT가 NSP loss를 이용해서 학습했을 때 Question-answering NLI(QNLI), Multi-genre NLI(MNLI), SQuAD 데이터 태스크를 더욱 잘 수행하였기 때문이다. 한편, (Lample and Conneau, 2019) 등 여러 연구들은 NSP loss의 필요성에 대한 의문을 제시했다. 이러한 간극을 이해하기 위해서 RoBERTa는 다양한 실험을 통해 NSP loss의 효과를 입증하고자 했다.
실험1 : SEGMENT-PAIR with NSP
이 방식은 original BERT와 동일한 입력값 설정으로, 두 segment로 이루어진 입력값이 입력되지만, 통합 512 토큰 이하가 사용된다. 두 segment는 인접해 있을 수도 있고, 아닐 수도 있다.
실험2 : SENTENCE-PAIR with NSP
두 sentence(완전한 자연어 문장)로 이루어진 입력값이 입력된다. 이 경우, 512 토큰에 맞추어 가공한 segment에 비해 문장이 짧을 수 있으므로, 배치 사이즈를 늘림으로써 전체적인 토큰의 수가 실험1과 유사하도록 설정되었다. 두 sentence는 인접해 있을 수도 있고, 아닐 수도 있다.
실험3 : FULL-SENTENCES without NSP
통합 512 토큰 이하로 구성된, 인접한 sentence(완전한 자연어 문장)들로 이루어진 입력값이 입력된다. 이때 sentence는 두 문장 이상이 가능하다. 인접한 문장들이지만, 하나의 문서(document)를 넘어서는 경우, 다음 문서에서 문장을 샘플링하되, 다른 문서로 넘어갔다는 표시를 위해 별도로 특별한 separator 토큰을 추가 해준다. 그리고 NSP loss를 사용하지 않았다.
실험4 : DOC-SENTENCES without NSP
실험3과 유사하게 입력값을 구성한다. 그러나 하나의 문서를 넘어서는 문장 구성은 허용하지 않는다. 문서 끝에서 추출되는 문장들은 512 토큰보다 짧을 수 있으니, 이러한 경우 동적으로 배치 사이즈를 늘려줌으로써 조정했다. 그리고 NSP loss를 사용하지 않았다.
실험 결과
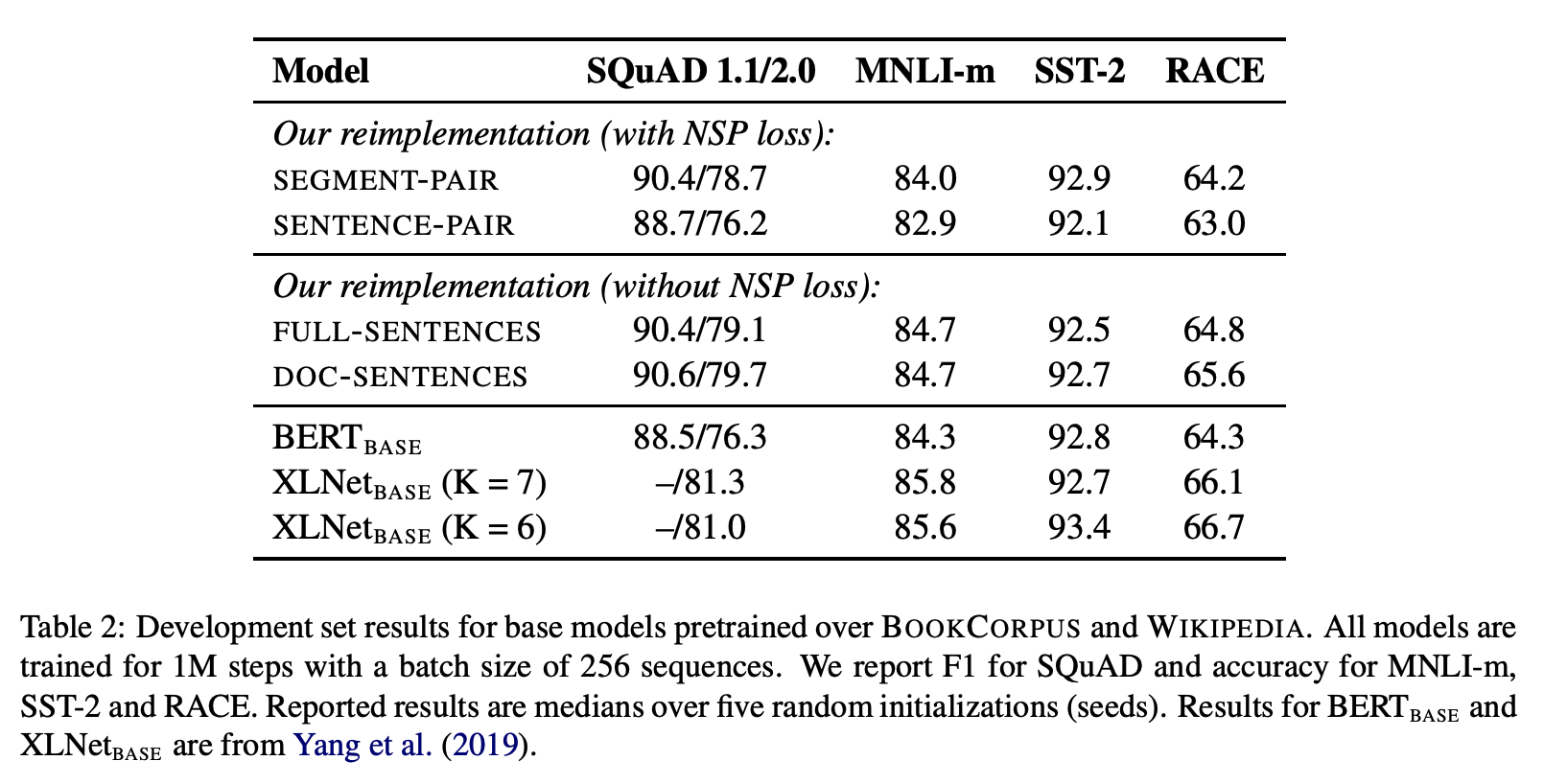
우선, 예상대로 실험2(SENTENCE-PAIR with NSP)는 original BERT의 방식인 실험1(SEGMENT-PAIR with NSP)에 비해 downstream task 성능이 떨어졌다. 이를 통해, sentence를 사용하는 경우, 문장이 짧을 때 long-range dependencies가 있을 수 있으며, 이에 따라 모델이 long-range 맥락을 학습할 수 없다는 가설을 입증했다.
또한, NSP loss를 제거했음에도 불구하고 downstream task의 성능 향상을 볼 수 있었다. 특히 실험4(DOC-SENTENCES without NSP)의 결과가 두드러졌지만, 매번 배치 사이즈를 동적으로 변경시켜주어야 한다는 불편함이 있어 이후 실험에서는 실험3(FULL-SENTENCES without NSP)의 방식을 활용했다고 한다.
특징3 - 더욱 긴 sequence로 학습
original BERT처럼 최대 512 길이의 토큰 sequence를 사용하되, 다른 점으로는 short sequence를 랜덤하게 사용하지 않았고, 처음 90%의 업데이트 동안 reduced sequence length를 사용하지 않았다.
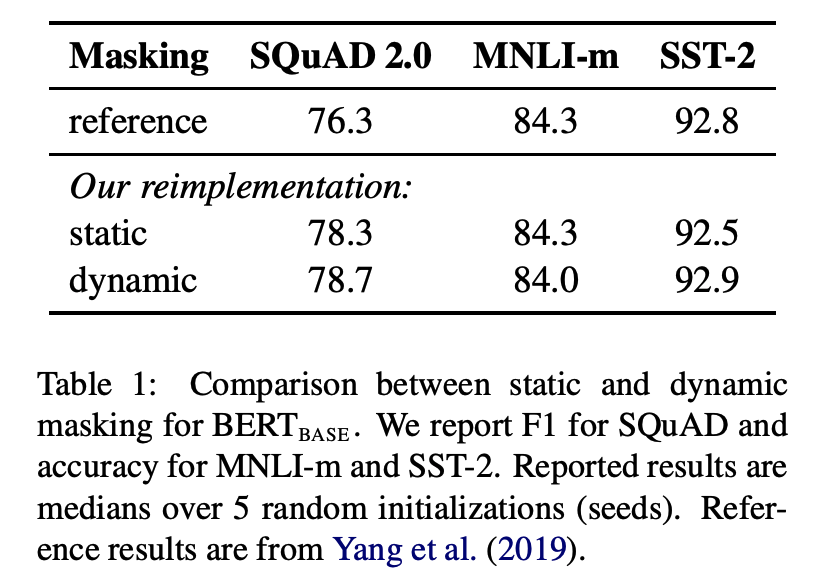
특징4 - 동적 마스킹 방식 적용
original BERT는 Masked Language Model(MLM) 학습 방식을 위해 [MASK] 토큰을 전처리 단에서 만들어사용한다. 이는 학습 단계에서 고정된 데이터이므로 static masking이라 할 수 있다. 이 경우, 모델은 매 epoch마다 동일하게 마스킹된 데이터를 중복하여 보게된다. RoBERTa에서는 [MASK] 토큰을 전처리 단계에서 만드는 것이 아니라, 모델에 텍스트 데이터가 주입되는 시점에 생성해서 사용한다. 이렇게 동적으로 데이터를 마스킹하는 방식을 dynamic masking 이라고 한다. dynamic masking 기법은 더욱 많은 텍스트 데이터를 활용하여 더욱 오래 사전학습하는 RoBERTa에 필수적이며, 실제로 downstream task 성능 향상에도 기여했다고 한다.
03. RoBERTa 실험 세팅
논문에서는 BERT-LARGE 크기의 아키텍처(레이어 수 = 24, 히든 사이즈 = 1024, 어텐션 헤드 수 = 16, 355M 파라미터)를 사용하였다. 1024개의 V100 GPU로 대략 하루 정도의 시간동안 학습했다.
04. RoBERTa 실험 결과
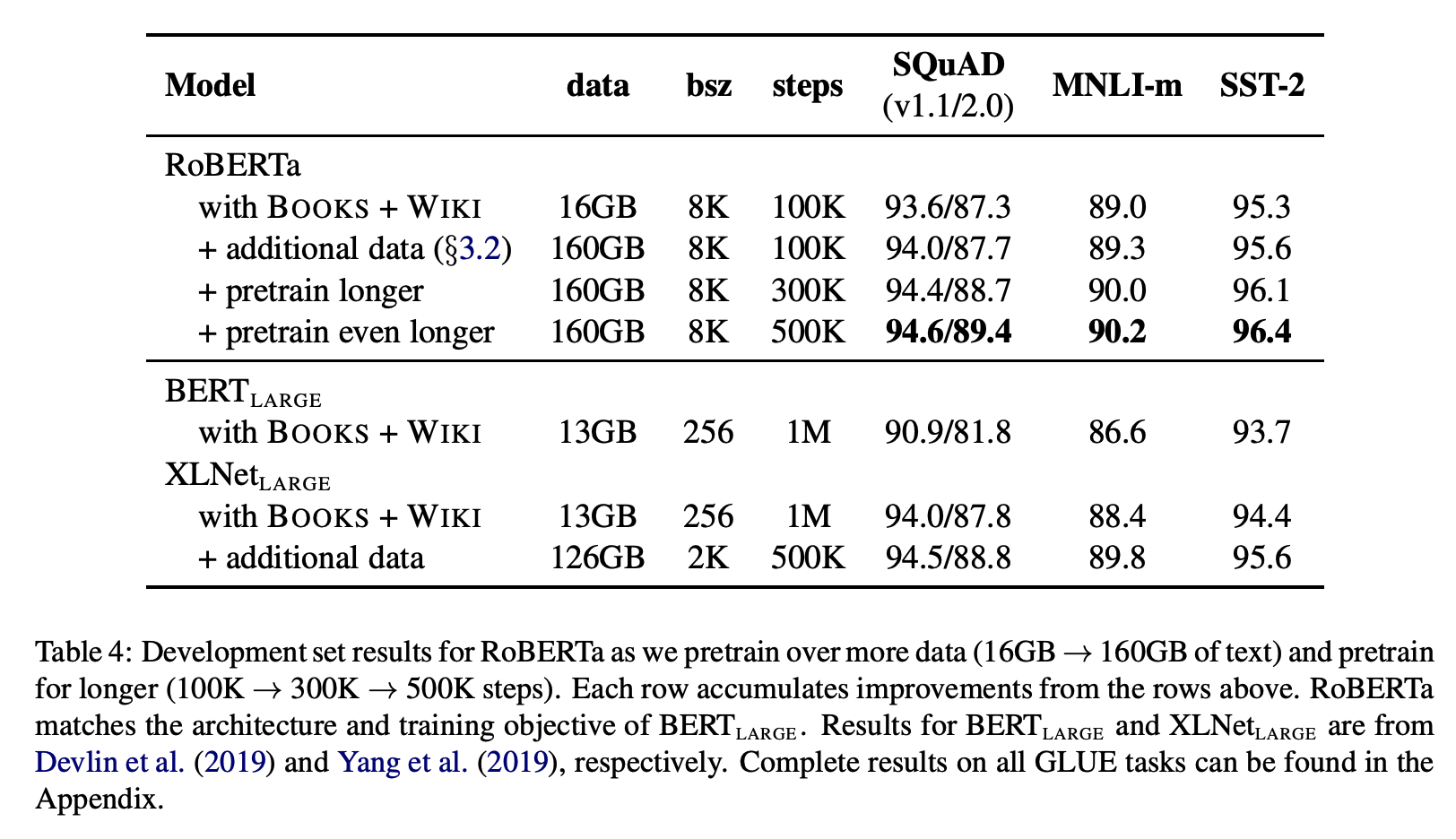
더욱 많은 데이터(data 160GB)로, 더 크게(bsz 8K), 더 오래(500K) 사전학습 할수록 성능이 좋아지는 것을 볼 수 있다.
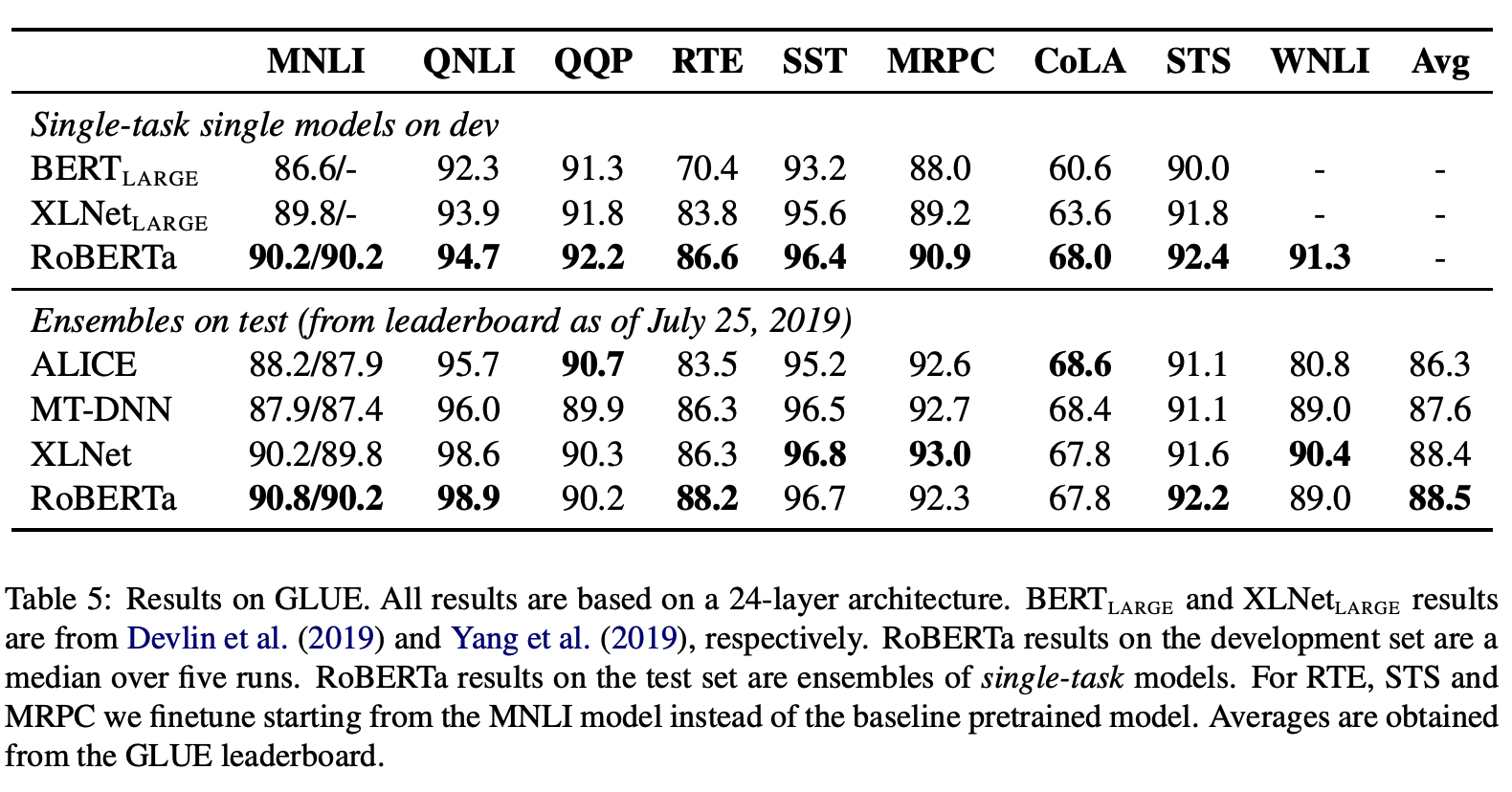
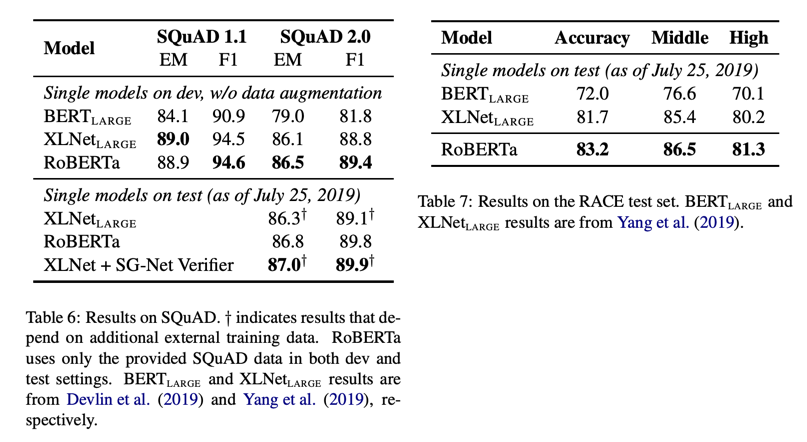
GLUE, SQuAD, RACE datasets로 실험한 결과들을 비교해보면, 많은 Natural Language Understanding(NLU) 태스크에서 RoBERTa가 SOTA를 달성하였다.
05. 참고 문헌
[1] 원 논문 : https://arxiv.org/pdf/1907.11692.pdf