이 포스트는 개인적으로 공부한 내용을 정리하고 필요한 분들에게 지식을 공유하기 위해 작성되었습니다. 지적하실 내용이 있다면, 언제든 댓글 또는 메일로 알려주시기를 바랍니다.
00. 들어가기에 앞서
2017년, Facebook AI에서 공개한 StarSpace는 그 구조가 간단하면서도 다양한 도메인의 내용들을 임베딩할 수 있다는 강력한 장점을 가지고 있다. 챗봇의 의도 분류기를 연구했던 시절에 처음 접했던 개념이었지만, 개인적인 필요에 의해 다시 한 번 살펴볼 일이 있어 이참에 본 포스트를 통해 정리하고자 한다.
원 논문 StarSpace: Embed All The Things!를 참고하기를 바란다.
01. Introduction
“a general-purpose neural embedding model”
StarSpace는 아래와 같이 다양한 문제들을 해결할 수 있는 신경망 임베딩 모델이다.
- 텍스트 분류 태스크 (자연어처리 분야)
- e.g., 감정 분석, 의도 분류 등
- 엔티티에 대해 랭크를 부여하는 태스크 (Information Retrieval 분야)
- e.g., 웹에서 쿼리를 날렸을 때, 웹 상의 수많은 도큐먼트들에 대해서 랭킹을 부여하는 등
- 협업 필터링 기반의 추천 (추천시스템 분야)
- 문서, 음악, 비디오 추천 등
- 이산적인 feature로 이루어진 콘텐츠에 대한 추천 (추천시스템 분야)
- e.g., 문서의 단어들 등
- 그래프 임베딩 (그래프 임베딩 분야)
- e.g., Freebase
- 기타 단어, 문장, 문서 등에 대한 임베딩 등등
StarSpace 모델은 이처럼 다양한 분야에서 임베딩 태스크들에 응용할 수 있다는 특징으로 그 이름이 지어졌다. Star는 *, 즉, 모든 엔티티 타입을 의미하며, Space는 임베딩 공간을 의미하는데, 풀어보자면, 엔티티 타입이 어떠하든 모든지 한 공간에 임베딩 할 수 있다고 해석할 수 있다.
02. Model
02-1. 이산적인 특징 벡터를 입력 받는 StarSpace
StarSpace 모델을 통해 임베딩 하고자 하는 entity는 이산적인(discrete) 특징을 가진다. 대표적인 예로는 단어의 수를 셈하여 만드는 BOW(Bag-Of-Words) 벡터가 있겠다. 풀고자하는 태스크에 따라 꼭 단어가 아니더라도, 특정 유저가 좋아요를 누른 영화나 물건 등과 같이 이산적으로 표현할 수 있는 특징이면 StarSpace 모델을 활용하기에 적합하다.
(허나, 필자의 개인적인 생각과 경험으로는, 반드시 이산적인 특징 벡터만 가능한가 싶다. 예컨대 실수 값으로 이루어진 TF-IDF 벡터도 입력값으로 쓸 수 있어 보인다.)
02-2. 서로 다른 종류의 엔티티를 같은 공간 상에 임베딩하는 StarSpace
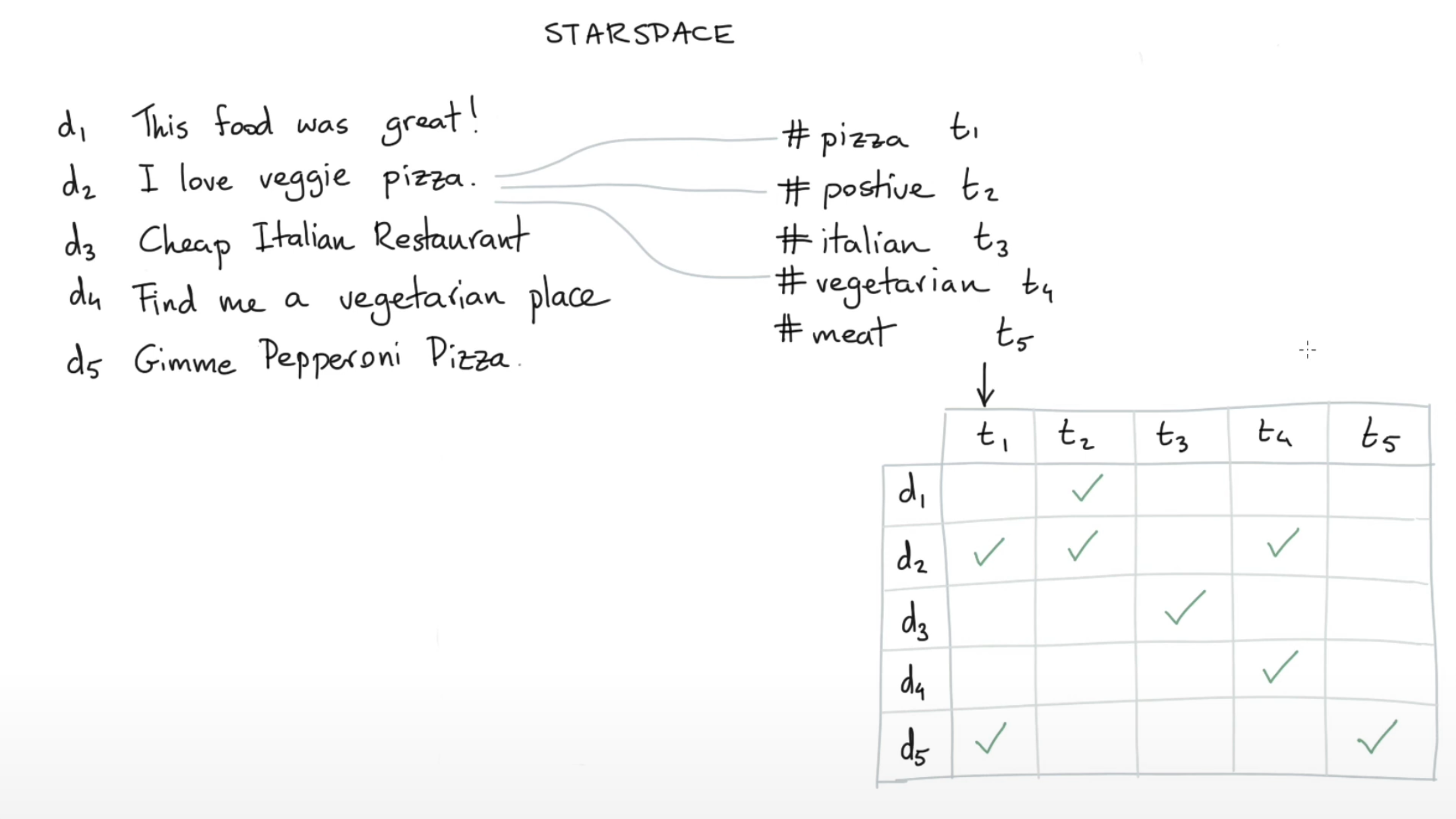
StarSpace의 가장 강력한 특징은 서로 다른 종류의 엔티티를 같은 공간 상에 임베딩 할 수 있다는 점이다. ‘서로 다른 종류의 엔티티’란 뭘까? 예를 들면, 사람들이 올려놓은 게시글과, 이에 대해서 부여된 해시태그들이라고 생각해볼 수 있겠다.
 [출처 : Rasa Algorithm Whiteboard (Youtube)]
[출처 : Rasa Algorithm Whiteboard (Youtube)]
위 그림을 살펴보자.
(d2) : I love veggie pizza라는 document는 #pizza라는 해시태그가 달릴수도 있으며, #positive 및 #vegetarian이라는 해시태그 또한 달릴 수 있다. 또한 (d5) : Gimme Pepperoni Pizza라는 document 역시 피자와 관련된 글이므로 앞선 문장처럼 #pizza의 해시태그가 달릴 수 있다. 이러한 관계들을 위의 그림과 같이 표(table) 형태로 표현할 수 있다.
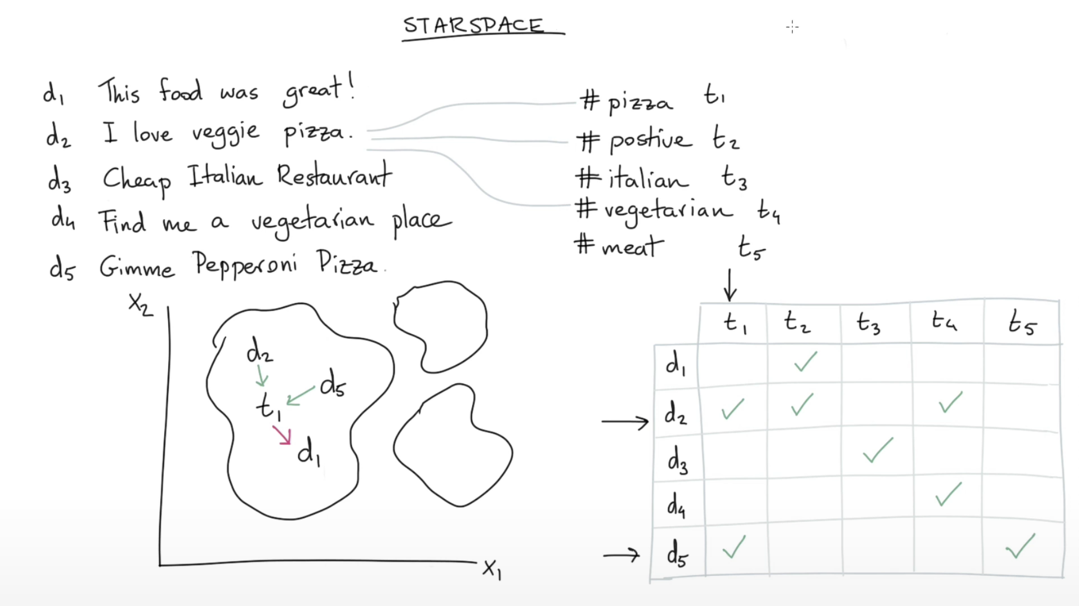
그렇다면 어떻게 해야 이러한 관계들을 이용하여 같은 공간 상에 임베딩 할 수 있을까?
 [출처 : Rasa Algorithm Whiteboard (Youtube)]
[출처 : Rasa Algorithm Whiteboard (Youtube)]
StarSpace 모델의 핵심은 동일한 레이블(e.g., 해시태그)이 부여된 엔티티(e.g., document)는 가깝게 임베딩되고, 다른 레이블이 부여된 엔티티는 멀리 임베딩 되도록 하는 메커니즘이다. 그렇게 학습을 마치고 나면, 엔티티 임베딩들과 레이블 임베딩들이 유사성을 기반으로 하여 일종의 클러스터를 이룰 것이다.
이는 StarSpace가 가지는 중요한 특징이라고 할 수 있다. BERT와 같이 대규모 일반 도메인 말뭉치를 활용하여 학습하는 언어모델과 달리, 우리가 가지고 있는 엔티티에 해당하는 도메인으로 학습하기 때문에, 특정 closed domain task를 풀 때 훨씬 유용하게 사용될 수 있다. 이러한 특징 때문에 Rasa에서 StarSpace를 시나리오 기반 챗봇의 의도 분류기로써 활용하는 것으로 생각된다.
02-3. 모델의 구조
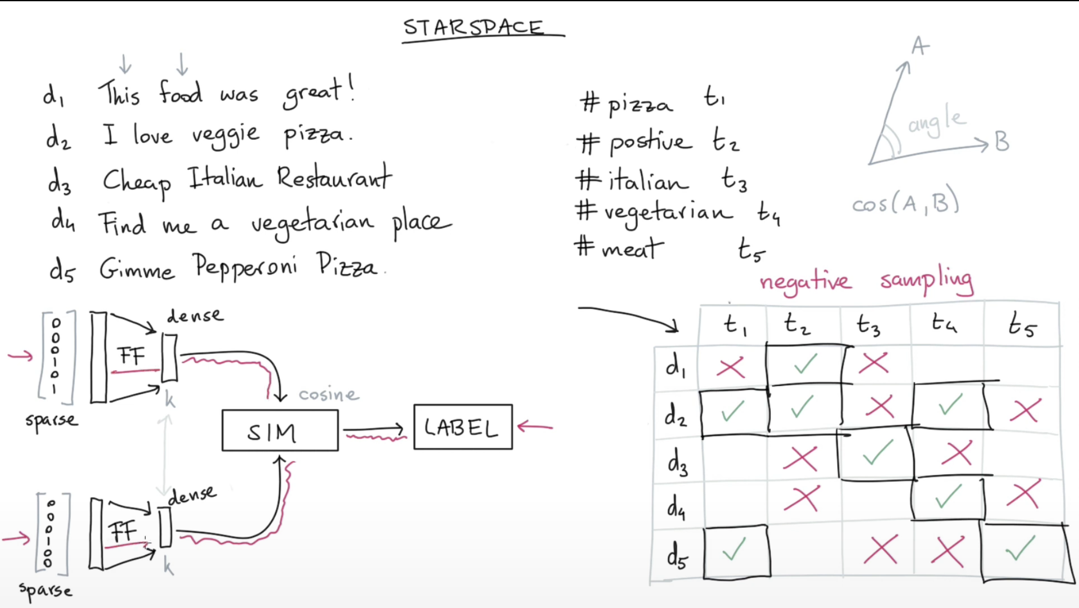 [출처 : Rasa Algorithm Whiteboard (Youtube)]
[출처 : Rasa Algorithm Whiteboard (Youtube)]
모델의 구조는 제법 심플하다. 엔티티에 대한 임베딩 및 레이블에 대한 임베딩을 각각 linear layer를 통과시켜 $k$ 차원의 공감에 projection 한다. 그후 코사인 유사도 또는 벡터의 내적을 통해 유사도 점수를 구한 후, 해당 점수와 레이블 간의 ranking loss를 구하는 방식이다.
 [출처 : https://cw.fel.cvut.cz/old/_media/courses/xp36vpd/vpdstarspace.pdf]
[출처 : https://cw.fel.cvut.cz/old/_media/courses/xp36vpd/vpdstarspace.pdf]
03. 구현
아래는 StarSpace를 참고하여 의도 분류를 구현한 코드의 예시다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
class StarSpace(nn.Module):
def __init__(self, X_dim, n_labels, emb_dim=32, drop_rate=0.5):
super().__init__()
# feature들에 대한 임베딩
self.feature_emb_layer = nn.Sequential(
nn.Linear(X_dim, 64),
nn.ReLU(),
nn.Dropout(p=drop_rate),
nn.Linear(64, emb_dim)
).to(device)
# 레이블에 대한 임베딩
self.label_emb = nn.Embedding(n_labels, emb_dim, max_norm=10.0).to(device)
self.label_emb_layer = nn.Sequential(
nn.ReLU(),
nn.Linear(emb_dim, emb_dim),
nn.ReLU(),
nn.Linear(emb_dim, emb_dim)
).to(device)
# loss
self.ce_loss = nn.CrossEntropyLoss() # Softmax + CrossEntropyLoss
self.softmax = nn.Softmax(dim=-1)
def forward(self, X, y):
# 임베딩 레이어를 통과하여 임베딩을 획득
feature_emb = self.feature_emb_layer(X)
# 어차피 positive target 임베딩과 negative target 임베딩이 함께 있음
y_embs = self.label_emb_layer(self.label_emb.weight)
# 정답에 대한 레이블의 스코어와 negative 레이블의 스코어가 함께 계산됨
sim_scores = torch.matmul(feature_emb, y_embs.transpose(0, 1))
loss = self.ce_loss(sim_scores, y)
confidence, prediction = torch.max(self.softmax(sim_scores), dim=-1)
return {"loss": loss, "prediction": prediction, "confidence": confidence}
04. 참고 문헌
[1] 원 논문 : StarSpace: Embed All The Things!
[2] Rasa Algorithm Whiteboard : StarSpace