이 포스트는 개인적으로 공부한 내용을 정리하고 필요한 분들에게 지식을 공유하기 위해 작성되었습니다. 지적하실 내용이 있다면, 언제든 댓글 또는 메일로 알려주시기를 바랍니다.
01. 개요
2015년, 구글에서 발표한 Listen, Attend and Spell(LAS)는 전통적인 DNN-HMM 모델과 달리 음성 인식에 사용되는 모든 컴포넌트를 결합하여 한번에 학습할 수 있는 end-to-end 방식을 제시한다. 또한 LAS는 당시 유명했던 Connectionist Temporal Classification(CTC) 방법론과 마찬가지로 음성 신호의 sequence $\mathbf{x}$가 주어졌을 때, 이에 맞는 토큰(참고로 LAS는 글자의 sequence)의 sequence $\mathbf{y}$ 간의 명시적인 정렬 관계(alignment) 없이도 학습할 수 있다. CTC와의 차이점으로는, CTC는 RNN(등의 sequence를 모델링하는 신경망)의 출력으로 나오는 음소의 sequence가 조건부 독립(conditional independence)임을 가정하는 반면, LAS는 이러한 가정 없앰으로써 더욱 효과적인 decoding이 가능하게 되었다. 예를 들어, CTC는 “triple a”라는 발화에 대해 “aaa”로 교정할 수 없으나, LAS는 조건부 독립 가정을 제거하여 더욱 풍부한 표현(i.e., multiple spelling variants)으로 출력할 수 있게 되었다. 그럼, 마치 NLP의 Seq2Seq 모델을 빼닮은 LAS를 살펴보자.
02. 훑어보는 LAS
주요 특징 요약
listener: pyramidal RNN으로 음성 신호 정보를 벡터로 encoding하는 encoder를 구현함- (참고) pyramidal RNN 형태가 아니면, 모델 학습이 지나치게 느리게 수렴됨
attention mechanism: decoding 시 음성 신호의 sequence에서 더욱 집중해야 할 곳을 포착할 수 있음- (참고) attention mechanism이 없이는 심각하게 학습 데이터에 과적합됨
speller: character sequence를 출력하여out-of-vocabulary(OOV)문제를 해결한 decoder를 구현함조건부 독립을 제거: 동일한 음성 sequnece가 주어져도 beam search에 따라 출력 sequence를 다양하게 표현할 수 있음
03. 조금 더 들여다보는 LAS
LAS가 로그-멜 스펙트럼(log-mel filter banks)을 입력으로 받는다고 할때, 입력되는 음성 신호의 sequence를 $\mathbf{x}=(x_1, x_2, …, x_T)$라고 표기한다.
또한 이에 대응되는 글자들의 sequence를 $\mathbf{y} = (<sos>, y_1, …, y_S, <eos>)$라고 한다. 이때 $y_{i} \in \{ a, b, c, … , z, 0, … , 9, <space>, <comma>, <period>, <apostrophe>, <unk> \}$이다.
LAS는 음성 신호 $\mathbf{x}$와 처음부터 이전 시점까지의 글자 출력 결과 $y_{<i}$가 주어졌을 때 글자의 출력 $y_i$가 나올 조건부 확률들을 chain rule을 이용하여 곱함으로써 $p(\mathbf{y} | \mathbf{x}) = \prod_i P(y_i | \mathbf{x} , y_{<i})$와 같이 입력 sequence와 출력 sequence의 관계를 모델링한다.
전반적인 아키텍처
LAS는 음향 모델의 encoder 역할을 수행하는 listener와 attention 기반으로 글자들을 출력하는 decoder인 speller로 구성된다. 일종의 Sequence2Sequence(Seq2Seq) 모델의 변형이라고 생각해도 좋을 것 같다. 이들은 $Listen$ 함수와 $AttendAndSpell$ 함수로 구현된다.
encoder인 listener는 원시 음성 신호 $\mathbf{x}$를 high level representation $\mathbf{h}=(h_1, …, h_U)$로 변환하는 역할을 한다. 이때 $U \le T$이며, $T$는 $\mathbf{x}$의 최대 길이를 의미한다. 추후 다룰 pyramidal 구조로 encoding을 하기때문에 이 조건은 당연하게 만족된다. 이는 다음과 같이 $Listen$ 함수로 표현한다.
$\mathbf{h} = Listen(\mathbf{x})$
한편 attention mechanism 기반의 decoder인 speller는 아래와 같이 표현한다.
$P(\mathbf{y} | \mathbf{x}) = AttendAndSpell( \mathbf{h}, \mathbf{y})$
이는 encoder를 통해서 encoding된 high level representation $\mathbf{h}=(h_1, …, h_U)$와 글자의 sequence $\mathbf{y}$(엄밀하게 말하면 이전 step까지의 글자 sequence $y_{<i}$)를 사용하여 현 시점에 나올 글자의 확률 $y_i$를 예측하는 역할을 한다. 즉, 최종적으로 $P(\mathbf{y} | \mathbf{x})$를 예측하는 모듈이라고 보면 되겠다.
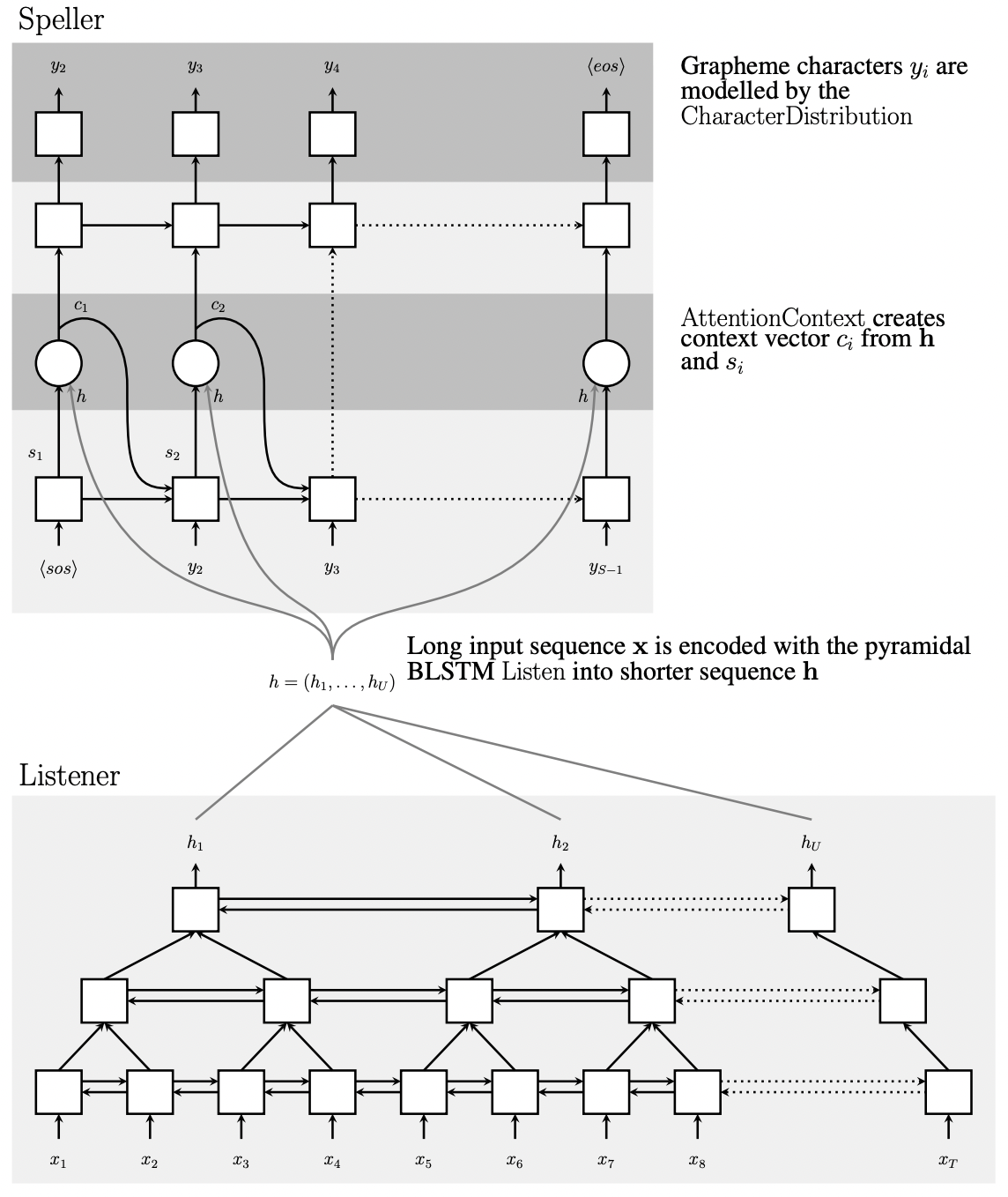
LAS의 전체적인 아키텍처는 위 그림과 같다. listener는 위와 같이 피라미드 모양으로 쌓은 양방향 LSTM을 사용하며, 음성 신호 sequence $\mathbf{x}$를 high level feature인 $\mathbf{h}$로 encoding 한다. speller는 attention을 활용하는 decoder이며, 매 time step마다 $\mathbf{h}$로부터 글자의 sequence $\mathbf{z}$를 생성해낸다.
Listen 함수
$\mathbf{h} = Listen(\mathbf{x})$ 함수를 살펴보도록 하자. 그림에서도 알 수 있듯이, listener에서는 음성 신호 sequence $\mathbf{x}$의 길이보다 더 적은 수의 $h_U$ representation들을 만들기 위해서 pyramidal BLSTM(pBLSTM)을 사용하였다. 왜냐하면, 음성 신호의 입력 값은 수백에서 수천 프레임으로 이루어질수 있기 때문이다. 이렇게 너무 많은 프레임으로 학습을 한다면, 아주 오랜 시간동안(심지어 약 한 달) 학습을 진행해도 모델의 수렴 속도가 너무 느려서 제대로 학습되지 않는 단점이 있다. 이는 $AttendAndSpell$ 함수 파트에서 attention 연산을 할 때, 매우 많은 입력 sequence 내에서 모델이 집중할 중요한 정보들을 파악하는데 많은 소요 시간이 걸리기 때문인 것으로 추정된다. 따라서 pBLSTM으로 $h_U$의 개수를 조절하여 computational complexity를 낮춤으로써 이러한 문제를 해결하고자 한 것이다.
pBLSTM을 수식으로 표현하면 $h_i^j =$ pBLSTM$(h_{i-1}^j , \left[ h_{2i}^{j-1} , h_{2i+1}^{j-1} \right])$으로 쓸 수 있는데, 이전 레이어의 hidden state를 concatenate($\left[ h_{2i}^{j-1} , h_{2i+1}^{j-1} \right]$ 부분)하여 BLSTM의 입력으로 사용함으로써 구현하는 것을 알 수 있다. 참고로 일반적인 BLSTM은 단순히 $h_i^j =$ BLSTM$(h_{i-1}^j , h_{i}^{j-1})$이다.
Attend and Spell 함수
decoder의 $AttendAndSpell( \mathbf{h}, \mathbf{y})$ 함수를 살펴보도록 하자. decoder는 매 time step마다 지금까지 보았던 글자들의 sequence $y_{<i}$ 정보를 토대로 다음 글자가 어떤 글자가 될 것인지 $y_i$에 대한 확률 분포를 생성한다.
이때 $y_i$에 대한 확률 분포는 (1) decoder의 state $s_i$와 (2) context vector $c_i$를 이용하여 만들어지며, 아래와 같이 표현할 수 있다.
$P(y_i | \mathbf{x}, y_{<i} = CharacterDistribution(s_i, c_i))$
이를 구성하고 있는 요소들을 하나씩 살펴보겠다.
decoder state
decoder state $s_i$는 (1) 이전 시점의 state $s_{i-1}$, (2) decoder에 의해 이전 시점에 생성되었던 글자 $y_{i-1}$, 그리고 (3) 이전 시점에 $\mathbf{h}$와 $s_{i-1}$ 을 활용하여 만들어졌으며 $h_U$ 벡터 중 어디에 더욱 집중할지가 반영된 이전 시점의 context vector $c_{i-1}$를 입력으로 받아 만들어지며, 아래와 같이 RNN 함수로 표현할 수 있다.
$s_i =$ RNN$(s_{i-1}, y_{i-1}, c_{i-1})$
이러한 decoder의 state $s_i$에는 $s_{i-1}$과 $y_{i-1}$을 사용하므로 지금까지 나왔던 글자들의 sequence 정보가 함축되어 있다고 해석할 수 있다. 또한 이전 시점 context vector $c_{i-1}$을 사용하므로 음성 신호 sequence에 어떤 부분이 집중적으로 고려되고 있는지에 대한 정보가 포함되어 있다고 볼 수 있다.
context vector
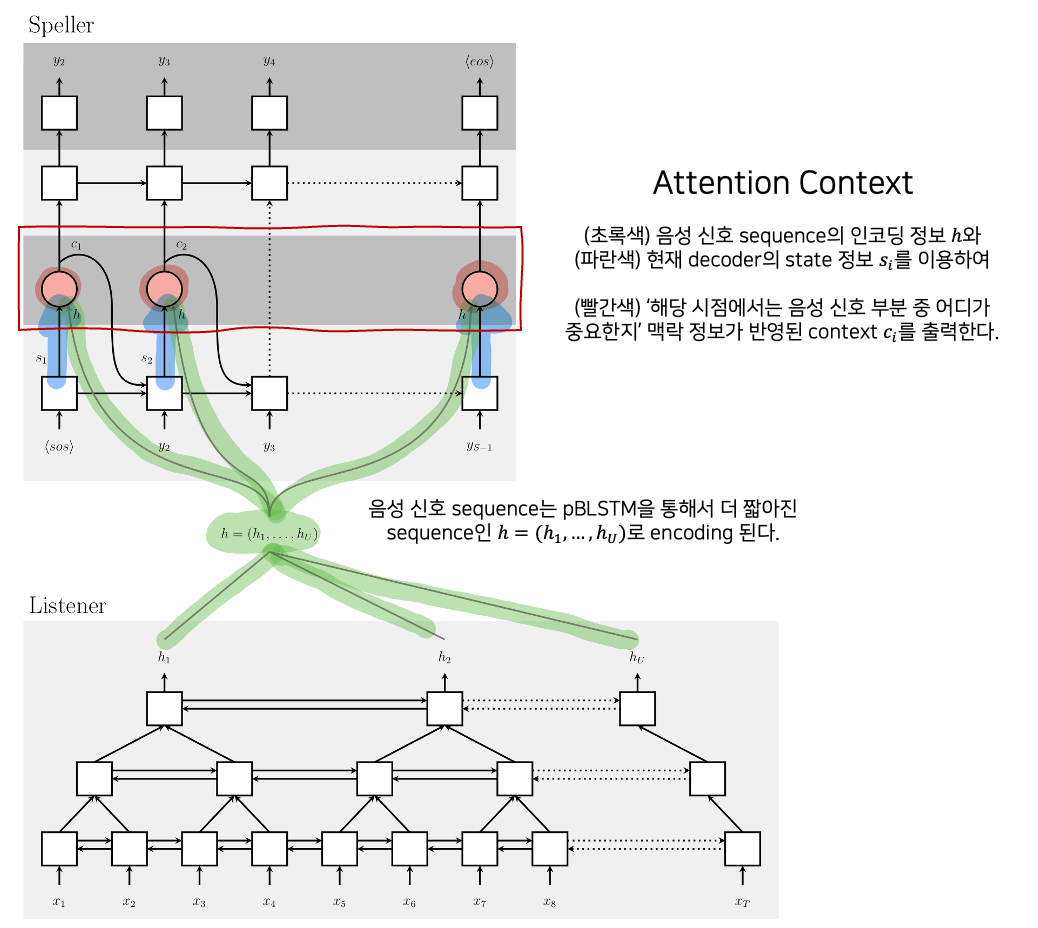
context vector $c_i$는 매 time step $i$마다 attention mechanism인 $AttentionContext$ 함수에 의해 생성되는데, 이는 다음 글자를 생성할 때 ‘음성 신호 부분 중 어느 부분이 특히 중요한지’ 맥락 정보가 반영된 벡터이다.
$c_i = AttentionContext(s_i, \mathbf{h})$
이러한 $c_i$를 출력해내는 $AttentionContext$ 함수에서는 어떤 일이 벌어지는지 살펴보도록 하겠다. decoder인 speller는 매 time step $i$마다 decoder state인 $s_i$와 음성 신호 sequence가 encoding된 $h_u \in \mathbf{h}$ 간의 scalar energy $e_{i, u}$를 계산한다.
$e_{i,u} = <\phi(s_i) , \psi(h_u)>$
$\phi$와 $\psi$는 MLP 레이어이며, $s_i$ 벡터와 $h_u$ 벡터 각각에 대해 MLP 레이어를 통과시킨 후 내적하여 scalar energe $e_{i, u}$를 구할 수 있다. 두 벡터 간 내적은 두 벡터가 유사할수록 큰 값이 되므로, 현 시점 decoder state와 가장 유사한 음성 신호 구간 $u$가 어디인지를 확인하고자 하는 것이다. 이 연산은 현 시점 $i$에서 모든 $u$개의 벡터 $h_u$에 대해 각각 계산된다. 예를 들어, 현재가 $i$=3 시점이라고 하면, $e_{i=3, 1}, e_{i=3, 2} … , e_{i=3, u}$ 와 같이 여러 scalar energy가 나온다.
이후, 지금까지 구한 scalar energy 들에 대해서 softmax 함수를 적용한다.
$\alpha_{i,u} = \cfrac{ \exp(e_{i,u}) }{ \sum_u \exp(e_{i,u}) }$
앞선 예시를 계속 이어서 하자면, $e_{i=3, 1}, e_{i=3, 2} … , e_{i=3, u}$ 와 같은 각각의 scalar energy들에 대해 softmax가 적용되는 것으로, 각각의 $e_{i, u}$ 값들은 energy의 크기대로 확률값처럼 변환된 $\alpha_{i,u}$로 변환된다. 따라서 당연하게도 $\sum_u \alpha_{i,u} = 1$이다.
$s_i$와 $h_i$의 관계에 대한 energy가 확률값처럼 변환된 $\alpha_{i,u}$는 time step $i$ 당시에 $u$번째 음성 신호 구간의 representation인 $h_u$가 얼마나 더 집중되어야 하는지에 대한 가중치다. 이제 이 가중치를 이용하여 $h_u$를 가중합 하면, time step i 당시에 u번째 음성 신호 구간 중 어디에 더 집중해야 하는지에 대한 정보가 담긴 맥락정보 $c_i$가 나온다.
$c_i = \sum_u \alpha_{i, u}h_u$
복잡한 과정 끝에 구한 $c_i$는 다음 시점에 decoder state를 구하는 과정에서 RNN의 입력값으로 사용된다. 이 복잡한 과정은 아래의 도식을 통해 정리할 수 있다.
학습 테크닉
$Listen$으로 구현되는 encoder인 listener 파트와 $AttendAndSpell$로 구현되는 decoder인 speller 파트는 동시에 결합되어(jointly) end-to-end로 학습된다. sequence to sequence 방식은 input 신호 $\mathbf{x}$와 이전 time step까지의 글자 sequence가 주어졌을 때 현재 글자를 예측하는 방식이므로 아래와 같은 로그 확률(log probability)를 극대화 하는 것을 목표로 한다.
$\max_\theta \sum_{i} \log P(y_{i} | \mathbf{x}, y_{<i}^{*} ; \theta )$
$y_{<i}^{*}$는 진짜 정답인 ground truth를 의미하는데, 학습을 마치고 실제 추론할 때는 현재 time step $i$ 이전까지의 글자 sequence 값들로 ground truth 값을 사용할 수는 없다. 따라서 추론 환경과 학습 환경 간의 불일치가 일어나게되어 강건하지 못한 성능의 원인이 된다.
LAS의 저자들은 이러한 문제를 해결하기 위해서 학습할 때 다음 글자를 예측하기 위해 이전 글자들을 항상 ground truth의 글자 sequence $y_{<i}^{*}$로 사용하는 것이 아니라, sampling 기법을 통해 추출한 $\tilde{y}_{<i}$를 활용하는 방식을 제시했다.
$\tilde{y}_i \sim \text{CharacterDistribution}(s_i, c_i)$
$\max_{\theta} \sum_{i} \log P(y_i | \mathbf{x}, \tilde{y}_{<i} ; \theta)$
구체적으로 10%를 sampling rate로 설정함에 따라, 90% 확률로는 ground truth에서 실제 정답을 활용하겠으나, 10%의 확률로는 $\tilde{y}_{i-1}$ 값을 글자의 분포에서 sampling을 하여 사용한다.
decoding and rescoring
학습이 완료된 이후의 추론은 음성 신호의 sequence $\mathbf{x}$가 주어졌을 때 이에 대응되는 가장 적합한 글자의 sequence $\hat{\mathbf{y}}$을 찾아야 한다.
$\hat{\mathbf{y}} = \arg \max_{y} \log P(\mathbf{y} | \mathbf{x})$
LAS의 저자들은 추론 시 decoding 전략으로 left-to-right beam search 알고리즘을 적용하였다. 여기에 더해 방대한 텍스트 데이터로 학습한 언어모델을 함께 활용하였다. 이때 LAS 모델이 예측하는 단어가 짧을 때 생기는 bias 문제를 해결하기 위해서 글자의 수 $|\mathbf{y}|_c$ 만큼 normalize를 적용했으며, 언어모델의 출력값을 beam score에 더해서 rescoring 하였다.
$s(\mathbf{y} | \mathbf{x}) = \cfrac{ \log P(\mathbf{y} | \mathbf{x})}{|\mathbf{y}|_c} + \lambda \log P_{LM}(\mathbf{y})$
04. 정리하며
LAS는 end-to-end 모델이면서도 CTC에서의 조건부 독립 가정 없이 음성 신호 sequence $\mathbf{x}$와 글자 sequence $\mathbf{y}$의 관계를 학습하는 데 성공했다. attention mechanism으로 CTC에서 복잡하게 구했던 $\mathbf{x}$와 $\mathbf{y}$ 간의 정렬 관계를 포착할 수 있다는 점이 대단히 흥미롭다.
05. 참고 문헌
Chan, William, et al. “Listen, attend and spell.” arXiv preprint arXiv:1508.01211 (2015).APA