이 포스트는 개인적으로 공부한 내용을 정리하고 필요한 분들에게 지식을 공유하기 위해 작성되었습니다.
지적하실 내용이 있다면, 언제든 댓글 또는 메일로 알려주시기를 바랍니다.
본 글은 ratsgo님의 speech book을 공부하고 정리한 글임을 밝힙니다.
01. Wave
- 단순파 웨이브 (simple wave)
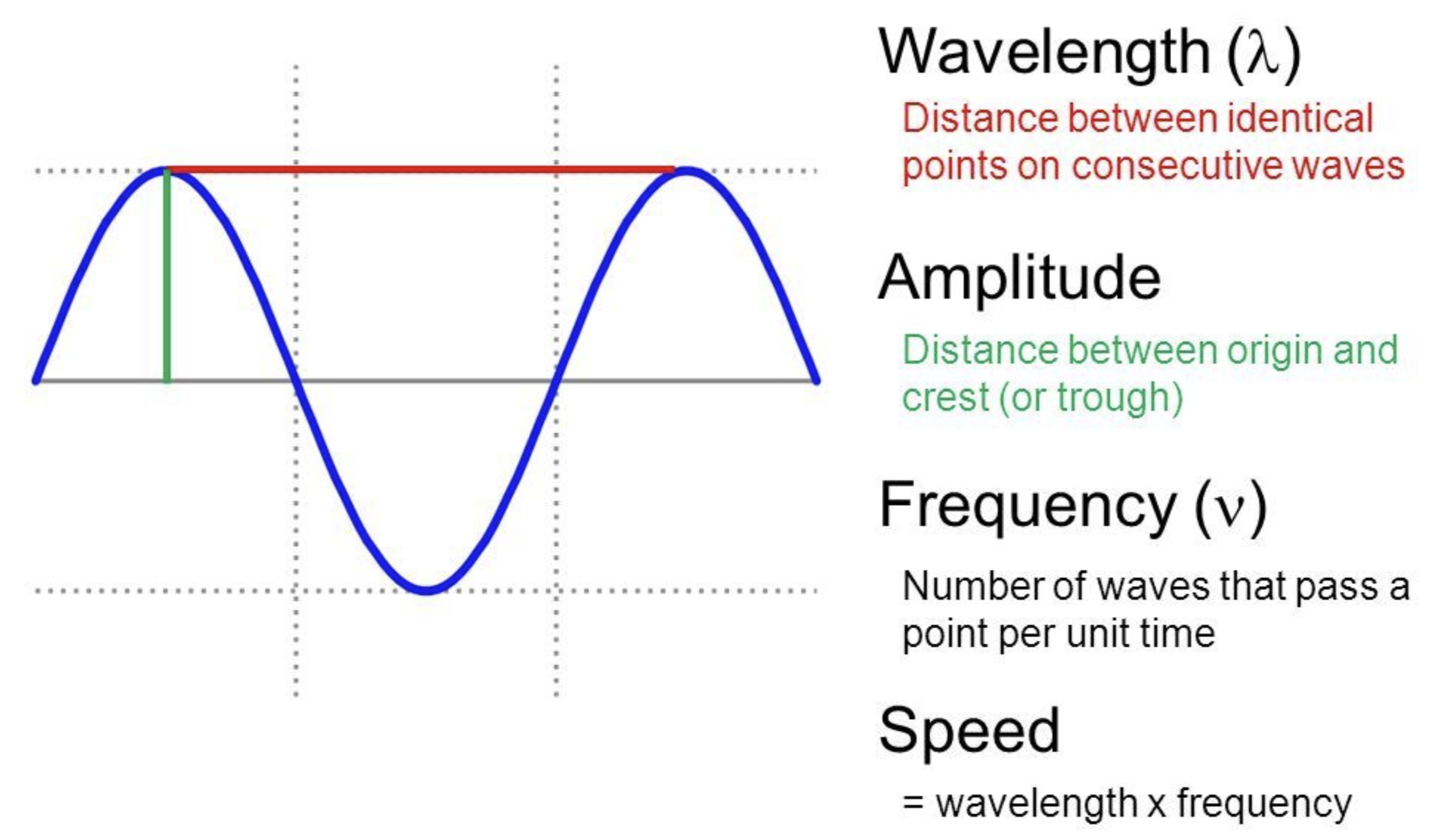
$x$축은 시간을 의미하며 $y$축은 음압(sound pressure)이 사용됨
![fig01]()
- 음압이란 공기 입자가 진동에 의해 인접 공기 입자를 미는 힘을 의미함
- 진폭 : 웨이브의 최댓값
- 주파수(frequency) : 1초에 몇 번 주기가 반복되는지 ⇒ 횟수
- 주파수 예 : 1초에 3회의 주기가 반복
- 주기(period) : 한 사이클을 도는 데 걸리는 시간
- 주기 예 : 1/3 (초)
- 주기 $T$와 주파수 $f$의 관계 : $T = \cfrac{1}{f}$
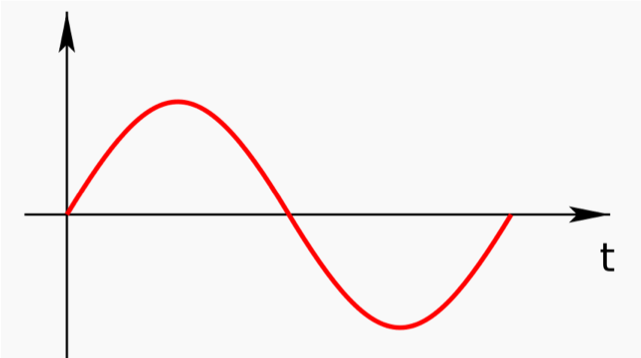
복합파
![fig02]()
- 단순파의 합으로 복합파의 형태를 나타낼 수 있음
- 깔끔한 곡선은 아니지만, 사이클이 반복되므로 주파수를 구할 수 있음

02. Digitization
- 아날로그 형태인 웨이브는 연속적인 값을 가지며, 이러한 신호를 컴퓨터가 처리하기 위해서는 디지털로 바꿔주어야 함
sampling
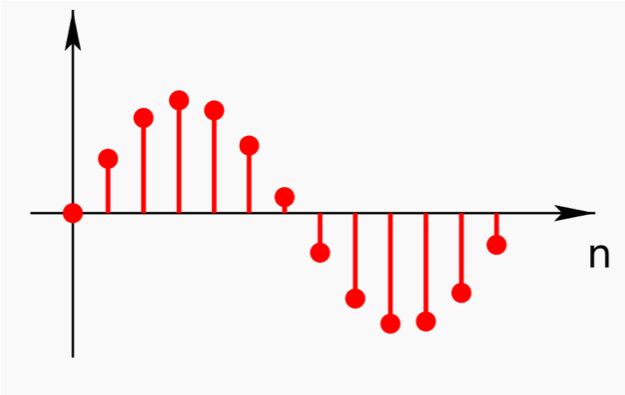
- 개념
- 일정한 시간 간격마다 음성 신호를 샘플해서 연속 신호를 이산 신호로 변환하는 과정을 의미함
- 초당 몇 번 sampling을 수행하는지를 나타내는 지표를
sampling rate라고 함- 1초에 4만 4,100번 sampling 한다면, sampling rate $f_s$는 44100, 또는 44.1KHz가 됨
- 즉, 1초에 해당하는 시간 동안 sampling 된 44,100개의 실수로 구성되어 있음
sampling된 디지털 신호의 아날로그 복원
- 나이퀴스트(Nyquist) 정리
- 모든 신호는 그 신호에 포함된 가장 높은 진동수의 2배에 해당하는 빈도로 일정한 간격으로 샘플링하면 원래의 신호를 완벽하게 기록할 수 있다는 이론
- 인간의 가청 주파수는 20~20000
(나이퀴스트 주파수)Hz인데, 40000Hz 이상의 sampling rate로 sampling하면 사람이 들을 수 있는 거의 모든 소리를 복원할 수 있음
- Anti-Aliasing
- 자연의 소리에는 나이퀴스트 주파수보다 높은 주파수 성분이 있을 수 있음
- 이에 따라 나이퀴스트 정리에 따라 sampling 해도 복원 시 왜곡이 있을 수 있으며, 이를 위해서
Anti-aliasing filter를 적용해야 함 - 이는, sampling을 적용하기 전, 아날로그 신호에 적용하여 나이퀴스트 주파수보다 높은 주파수 영역대를 미리 없애놓는 처리 방식임
Quantization
양자화(quantization)란 실수 범위의 이산 신호를 정수(integer) 이산 신호로 바꾸는 것을 의미함- 8비트 양자화 적용 시 : 실수 범위의 이산 신호가 -128~127 정수로 변환됨
- 16비트 양자화 적용 시 : 실수 범위의 이산 신호가 -32868~32767 정수로 변환됨
- 양자화에 따른 음성 정보 손실
- 양자화 비트 수가 커질수록 음성 정보 손실을 줄일 수 있으나, 저장 공간이 늘어나는 단점도 존재함
- 이러한 음성 정보 손실을 양자화 잡음(noise)라고 하며, 이를 줄이기 위해
압신(companding, 압축 & 신장) 기법을 사용함
03. Loudness
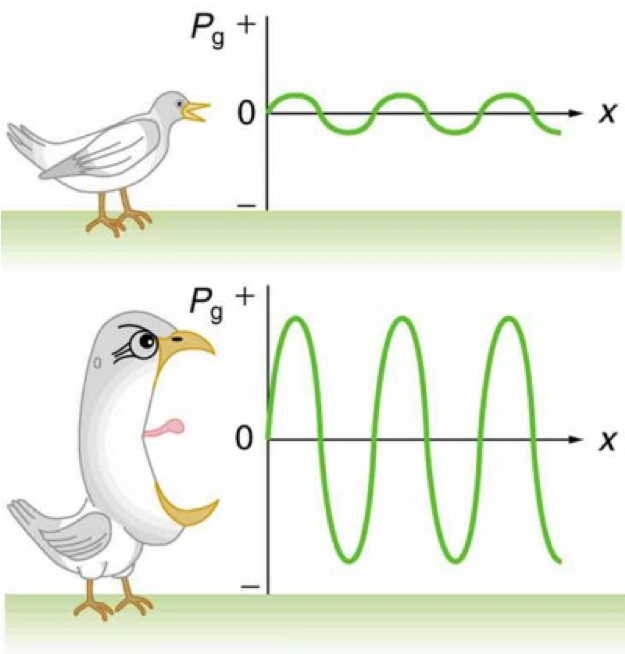
- 소리의 크기는 진폭(amplitude)와 직접 관련이 있음
- 소리 크기의 측정
- $N$은 이산 신호의 샘플 수를, $P_0$는 사람이 들을 수 있는 가장 작은 소리를 의미함
- $Power = \cfrac{1}{N}\sum_{i=1}^{N}x_i^2$
- $Intensity=10 log_{10}\cfrac{1}{NP_0}\sum_{i=1}^Nx_i^2$
- Intensity는 사람이 들을 수 있는 가장 작은 소리 대비 데시벨(dB) 기준으로 power가 얼마나 큰지 나타내는 지표임
- 사람은 특정 주파수 영역대의 신호는 상대적으로 큰 소리로 인식하므로, loudness가 위의 power 또는 intensity와만 관련있는 것은 아님
04. Pitch
- 음의 높낮이를 의미하며, 주파수와 관련이 있음
- 구간에 따른 주파수와 pitch의 관계
- 100Hz~1000Hz : pitch는 주파수와 선형 관계이며, 주파수가 커질수록 pitch 역시 높아짐
- 1000Hz 이상의 구간 : pitch는 주파수와 로그 관계이며, 주파수가 100배 정도 되어야 높낮이 차이를 2배라고 느끼는 정도임
- 즉, 인간은 저주파에 대해서 세밀하게 인식하고, 고주파는 세밀하게 인식하지 못함
- 사람이 인식하는 음의 높낮이 차이가 비슷하도록 주파수 영역대를 구분하여 pitch의 단계를 나눈 것이
멜 스케일(mel scale)임- $m=1127ln(1+\cfrac{f}{700})$
05. 인간의 음성 인식
lexical access
- 사람은 음성을 단어 단위로 인식하는데, 그 특성은 아래와 같음
- frequency
- 빈도 높은 단어를 빠르게 인식함
- parallelism
- 여러 단어(예컨대 두 명의 화자가 발화)를 한번에 알아들을 수 있음
- cue-based processing
- 인간의 음성 인식은 다양한 단서(cue)에 기반함
cue-based processing
음성적 단서(acoustic cue) 기반의 인식
- 포만트(formant)
- 포만트란, 스펙트럼에서 음향 에너지가 몰려 있는 봉우리를 가리키며, 어떤 주파수 영역대에서 형성되어 있는지에 따라 사람이 말소리를 다르게 인지함
- 성대 진동 개시 시간(voice onset time)
- 성대 진동 개시 시간은 무성폐쇄음(ㅍ)의 개방 단계 후에 후행하는 모음을 위해 성대가 진동하는 시간 사이의 기간을 의미하며, 말소리에서 유성자음과 무성자음을 식별하는 단서임
어휘적 단서(lexical cue) 기반의 인식
- 음소 복원 현상(phonemic restoration effect)
- 단어를 이루는 음소(phenome) 가운데 하나를 기침 소리로 대체하더라도 해당 음소를 들은 것으로 인지한다는 개념으로, 청자가 해당 어휘를 이미 알고 있기 때문임
시각적 단서(visual cue) 기반의 인식
- 맥거크 효과(McGurk effect)
- 입모양 또는 기타 다른 감각 정보의 영향으로 실제와는 다른 소리로 지각되는 현상을 의미하며, ‘ga’를 발음하는 영상을 보여주면서 ‘ba’ 소리를 들려주면 ‘da’라고 알아들음
on-line processing
- 실시간 인식
- 인간은 단어 세분화(word segmentation), 구문 분석(parsing), 그리고 해당 문장 해석(interpretation)까지 250ms 안에 처리할 수 있는 능력을 가짐
06. 참고 문헌
[1] ratsgo 님의 블로그