이 포스트는 개인적으로 공부한 내용을 정리하고 필요한 분들에게 지식을 공유하기 위해 작성되었습니다. 지적하실 내용이 있다면, 언제든 댓글 또는 메일로 알려주시기를 바랍니다.
00. 들어가며
음성 전문가의 도메인 지식과 푸리에 변환 등을 거쳐 추출해내는 음성 신호인Mel-Frequency Cepstral Coefficients(MFCC)와는 달리, 최근에는 뉴럴 네트워크(Neural Network) 기반의 음성 신호 특징 추출이 많이 활용되고 있다. MFCC를 활용하여 음성 신호의 특징(feature)을 추출하기 위해서는 매우 복잡한 도메인 지식과 공식들이 적용되는 반면, 뉴럴 네트워크 기반의 특징 추출 방식은 많은 음성 도메인 지식을 필요로 하지 않는다는 장점이 있다.
본 포스트는 대표적인 뉴럴 네트워크 기반의 음성 신호 특징 추출 방식인 Wav2Vec(1.0)을 톺아보고자 한다. 최근에는 Wav2Vec(2.0)까지 공개되었으나, 이 글에서는 우선적으로 Wav2vec(1.0) 버전을 살펴보고자 한다.
01. 개요
Wav2Vec이 나오기 이전(2019년도 이전), 음성 인식 모델이 좋은 성능을 보이기 위해서는 음성 신호가 텍스트로 전사되어 있는 대량의 데이터가 필요했다. 한편, 컴퓨터 비전이나 자연어처리 분야에서는 대량의 unlabeled 데이터를 이용하여 모델이 pre-training을 통해 대규모 일반 지식을 습득하고, 소규모의 labeled 데이터를 이용하여 downstream task에 fine-tuning 되는 방식이 큰 효과를 보여왔다. 음성 인식 task에서는 특히나 음성 오디오 신호가 텍스트 형태로 전사되어 있는 데이터를 구하기 어려운데, 이러한 문제를 해결하기 위해서 Wav2Vec은 unsupervised pre-training을 적용하고자 했다. 즉, 상대적으로 훨씬 수집하기에 수월한 unlabeled 오디오 데이터를 활용하여 pre-training을 수행하겠다는 것이다.
이렇게 pre-training된 Wav2Vec 모델은 원시 음성 오디오 신호를 입력받아서 general representation을 출력하게 되는데, 이때의 출력은 speech recognition system의 입력으로 활용된다. 목적식으로는 negative 오디오 샘플로부터 true 오디오 샘플을 구별해내는 contrastive loss를 활용한다.
02. 모델
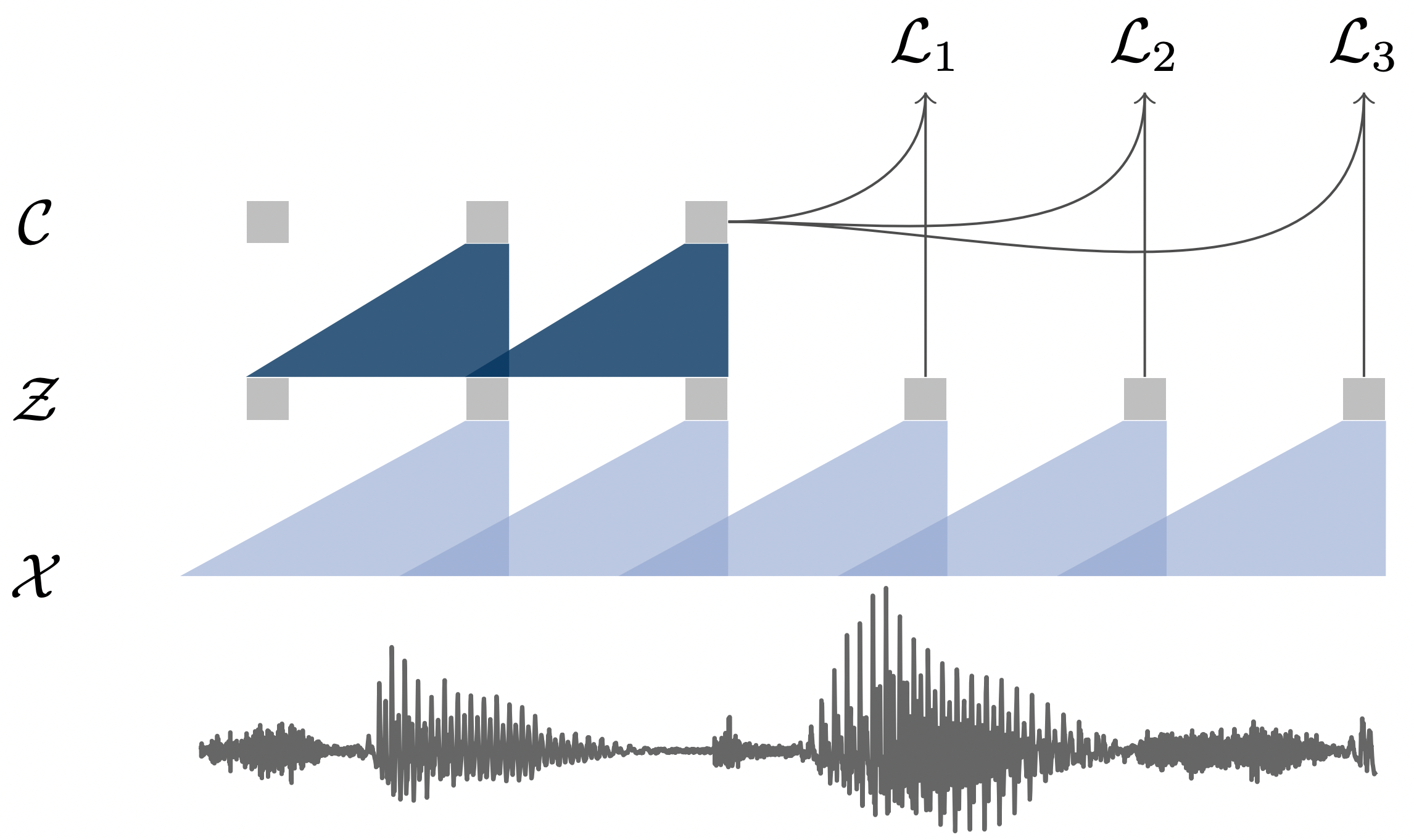 오디오 데이터 $\mathcal{X}$로부터 pre-training 되는 과정
오디오 데이터 $\mathcal{X}$로부터 pre-training 되는 과정
Wav2Vec은 두 개의 convolution neural network가 쌓여 있는 구조로, 네트워크 $f:\mathcal{X} \mapsto \mathcal{Z}$를 encoder network, $g: \mathcal{Z} \mapsto \mathcal{C}$를 context network라고 부른다.
encoder network $f$는 5층짜리 CNN으로 구성되었고, 원시 음성 신호 $\mathbf{x}_i \in \mathcal{X}$를 입력으로 받아서 low frequency feature representation $\mathbf{z_i} \in \mathcal{Z}$로 인코딩한다. 간단히 말해, 오디오 시그널을 latent space $\mathcal{Z}$로 임베딩했다고 보아도 무방할 것이다.
context network $g$는 9층짜리 CNN으로 구성되었고, encoder network로부터 나오는 multiple latent representation $\mathbf{z}_i, …, \mathbf{z}_{i-v}$를 single contextualized tensor $\mathbf{c}_{i}=g(\mathbf{z}_i, …, \mathbf{z}_{i-v})$로 변환한다. 이는 인코더로부터 나온 여러 타임 스텝들을 하나로 묶어주는 역할을 수행하는데, 이 과정에서 각 타임 스텝 representation의 맥락이 파악된다.
encoder network와 context network 모두 512 채널의 causal convolution network가 적용되었고, group normalization 및 ReLU 등이 적용되었다. 참고로, causal convolution이란, 다음 레이어에 미래의 값이 들어가지 않는 형태를 의미한다.
03. 목적식
[수식01] $\mathcal{L}_k=- \sum_{i=1}^{T-k}(\log \sigma ({\mathbf{z}\top_{i+k}} {h_k(c_i)}) + \lambda \mathbb{E}_{\mathbf{\tilde{z}} \sim p_n}[\log \sigma (-{\mathbf{\tilde{z}}\top} {h_k}(c_i))])$
Wav2Vec은 위의 contrastive loss를 최소화하며 학습한다. Wav2Vec은 학습과정에서 매 스텝 $k=1, …, K$ 마다 true(positive) sample인 $\mathbf{z}_{i+k}$를 negative sample인 $\mathbf{\tilde{z}}$로부터 구별하는 task를 수행한다. $\sigma$는 시그모이드 함수이며, $\sigma ({\mathbf{z}\top_{i+k}} {h_k(c_i)})$는 true sample의 확률이 된다. 이때 $h_k(c_i)=W_k \mathbf{c}_i+\mathbf{b}_k$는 affine transformation이다. 쉽게 말해, FC layer 한개라고 보면 되겠다. 또한 $\lambda$는 negative sample의 수를 의미한다. 한편, $\mathbf{\tilde{z}}$는 현재 배치의 다른 음성의 hidden representation들 가운데 랜덤으로 추출하여 만든다.
[수식02] $\mathcal{L}= \sum_{k=1}^K \mathcal{L}_k$
최종적으로는 매 $k$ 스텝에서 구해진 loss들의 합을 최소화하면서 학습되는데, 그 과정에서 true sample로 이루어진 쌍($\mathbf{z}_{i+k}$와 $h_k(c_i)$) 관계의 representation은 벡터 공간에서 가까워지고, 네거티브 쌍은 멀어지게 된다. 즉, encoder network와 context network가 입력 음성의 다음 시퀀스가 무엇일지에 관한 정보를 음성 피처에 녹여내는 것이다.
04. 기타
데이터
TIMIT, WSJ, Librispeech 데이터셋을 사용하였으며, 모두 16kH의 sampling rate로 구성된 영어 오디오 데이터이다.
디코딩
디코딩 과정에서는 4-gram KenLM 언어모델, word-based convolution 언어모델, character-based convolution 언어모델이 활용되었다.
코드 예시
1
2
3
4
5
6
7
8
9
10
11
import torch
from fairseq.models.wav2vec import Wav2VecModel
cp = torch.load('/path/to/wav2vec.pt')
model = Wav2VecModel.build_model(cp['args'], task=None)
model.load_state_dict(cp['model'])
model.eval()
wav_input_16khz = torch.randn(1, 10000)
z = model.feature_extractor(wav_input_16khz)
c = model.feature_aggregator(z)
05. 참고 문헌
[1] Schneider, Steffen, et al. “wav2vec: Unsupervised pre-training for speech recognition.” arXiv preprint arXiv:1904.05862
[2] ratsgo 님의 블로그
[3] 김정희 님의 발표자료