이 포스트는 개인적으로 공부한 내용을 정리하고 필요한 분들에게 지식을 공유하기 위해 작성되었습니다. 지적하실 내용이 있다면, 언제든 댓글 또는 메일로 알려주시기를 바랍니다.
00. 들어가며
Wav2Vec과 같이 뉴럴 네트워크 기반의 음성 신호 특징 추출 기법이 개발되기 전에는 음성 도메인 지식과 공식들에 기반하여 음성 신호의 특징을 추출하였다. 대표적인 전통적 음성 신호 특징 방법으로는 바로 Mel-Frequency Cepstral Coefficients(MFCC)가 있으며, 이는 뉴럴 네트워크 기반의 특징 추출기와는 달리 deterministic한 방법론이다. 본 포스트는 MFCC를 만드는 과정을 톺아보며 전통적인 음성 신호 특징 추출 방식을 정리한다.
01. 배경지식
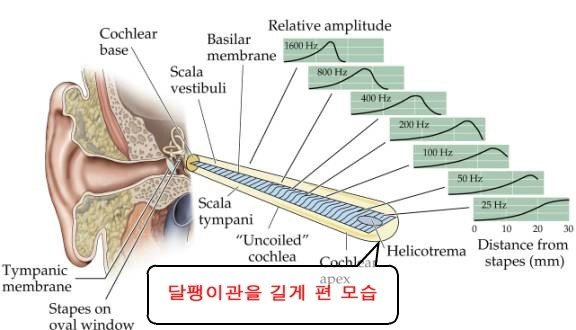
- 달팽이관
- 달팽이관은 귀의 가장 안쪽인 내이에 위치하며 듣기를 담당하는 청각기관임
- 돌돌 말려있는 달팽이관을 펼치면, 달팽이관의 각 부분은 각기 다른 주파수를 감지하고, 사람은 이러한 주파수에 따른 진동수를 기반으로 소리를 인식함
- 주파수가 낮은 저주파 대역에서는 주파수의 변화를 잘 감지하지만, 주파수가 높은 고주파 대역에서는 주파수의 변화를 잘 감지하지 못하는데, 그 이유는 달팽이관이 고주파 대역을 감지하는 부분으로 갈수록 얇아지기 때문임
- 따라서 특징벡터를 단순히 주파수를 쓰기 보다는 달팽이관의 특성에 맞추어 스케일링 하는 것이 더욱 효과적인데, 이를 Mel-scale이라고 함
- 음성 데이터 길이를 음소(현재 내고 있는 발음) 단위로 변환
- 사람마다 특정 문장을 발음하는 길이는 천차만별이기 때문에, 음성 신호에 대해서 음소 단위로 쪼개어 그 길이를 변환할 필요가 있음
- 통상적으로 20~40ms면 음소가 해당 시간 내에 바뀔 수 없다는 연구 결과를 바탕으로, MFCC는 음성 데이터를 20~40ms 단위로 쪼개고, 이에 대해서 특징(feature)으로 활용함
02. MFCC 알고리즘
💡 MFCC : Mel-Frequency Cepstral Coefficient의 약자로, ‘음성 데이터’를 ‘특징 벡터’로 변환해주는 알고리즘을 의미함
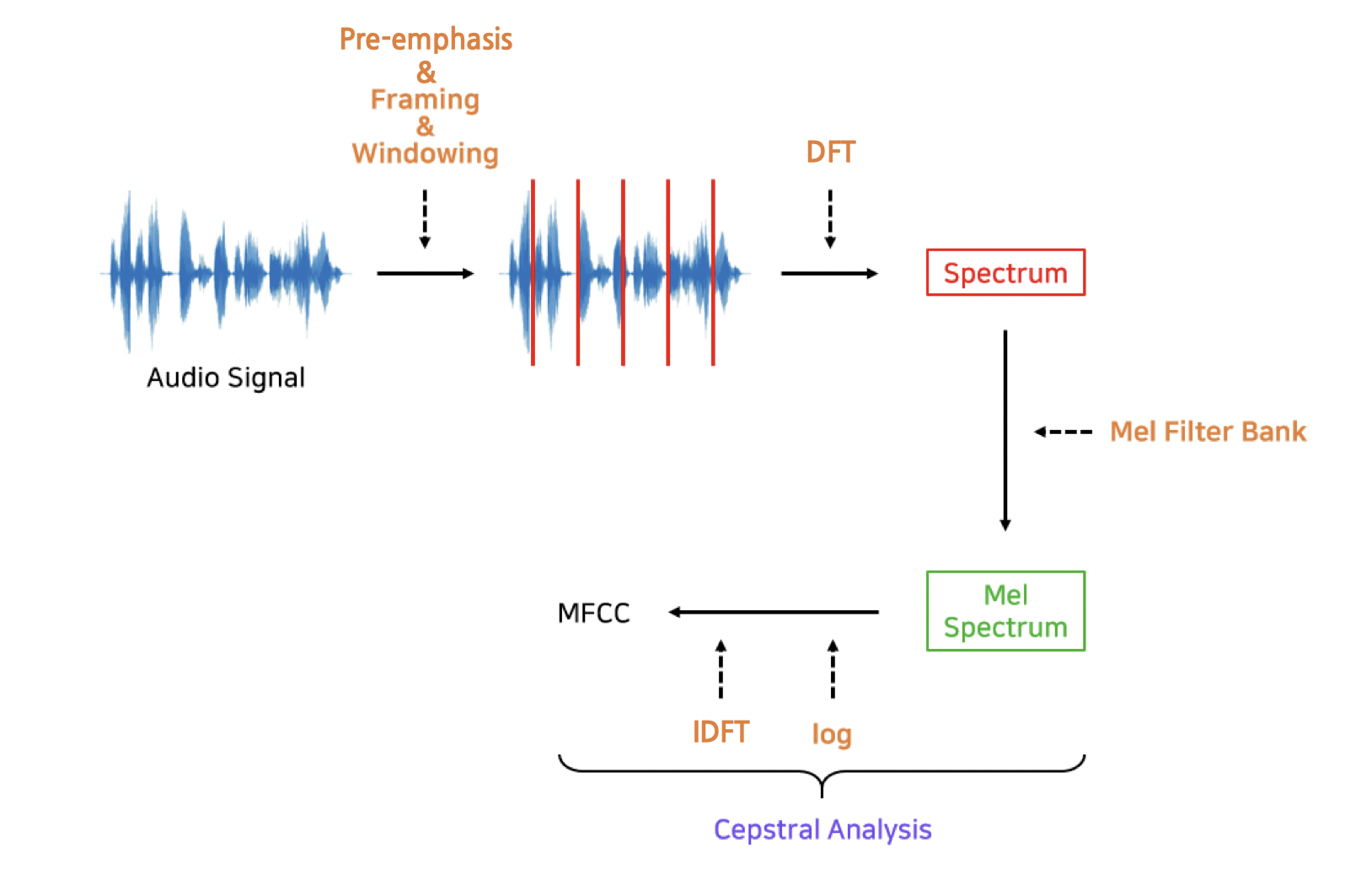
Pre-emphasis
- High-pass Filter
- 사람이 발성할 때 몸의 구조 때문에 실제로 낸 소리에서 고주파 성분이 상당량 줄어들어 나오게 되며, 이러한 경향은 모음을 발음할 때 두드러짐
- 따라서, 고주파 성분을 강화해주면 음성 인식 모델의 성능을 개선할 수 있으므로, 고주파 성분을 강화하기 위해 high-pass filter를 적용함
- 효과
- 고주파 성분을 강화해줌으로써 원시 음성 신호가 전체 주파수 영역대에서 고르게 분포됨
- 푸리에 변환 시 발생할 수 있는 numerical problem 예방
- Signal-to-Noise Ratio(SNR) 개선
- 방법
- $Y_t=X_t-\alpha X_{t-1}$
- $\alpha$ 는 보통 0.95나 0.97을 많이 씀
Sampling and Windowing
- fraiming
- 분석 대상이 지나치게 긴 경우 빠르게 변화하는 신호의 주파수 정보를 정확히 파악하기 어려움
- 따라서, 앞서 pre-emphasis 과정을 거친 신호에 대해서 신호를 20~40ms 단위로 분할함
- 프레임 끼리의 연속성을 위해서 분할된 신호를 50% 정도(약 10ms)씩 서로 겹추어 둠
- windowing
![fig03]()
- 일반적으로 원시 음성 신호를 짧은 구간 단위로 쪼개는 것은
rectangular window를 적용한 것인데, 이는 프레임의 양 끝에서 신호가 살아 있다가 갑자기 죽는 현상이 발생하며, 이로 인해 푸리에 변환 시 불필요한 고주파 성분이 살아남게 됨 - 따라서 각각의 프레임에 특정 함수를 적용하여 경계를 스무딩하는 기법을 사용하는데, 대표적으로는
해밍 윈도우(hamming window)라는 함수가 있음 - 해밍 윈도우
- $w[n] = 0.54 - 0.46 \cos{\cfrac{(2 \pi n)}{N-1}}$
- $n$은 해밍 윈도우 값 인덱스, $N$은 프레임 길이
- 일반적으로 원시 음성 신호를 짧은 구간 단위로 쪼개는 것은

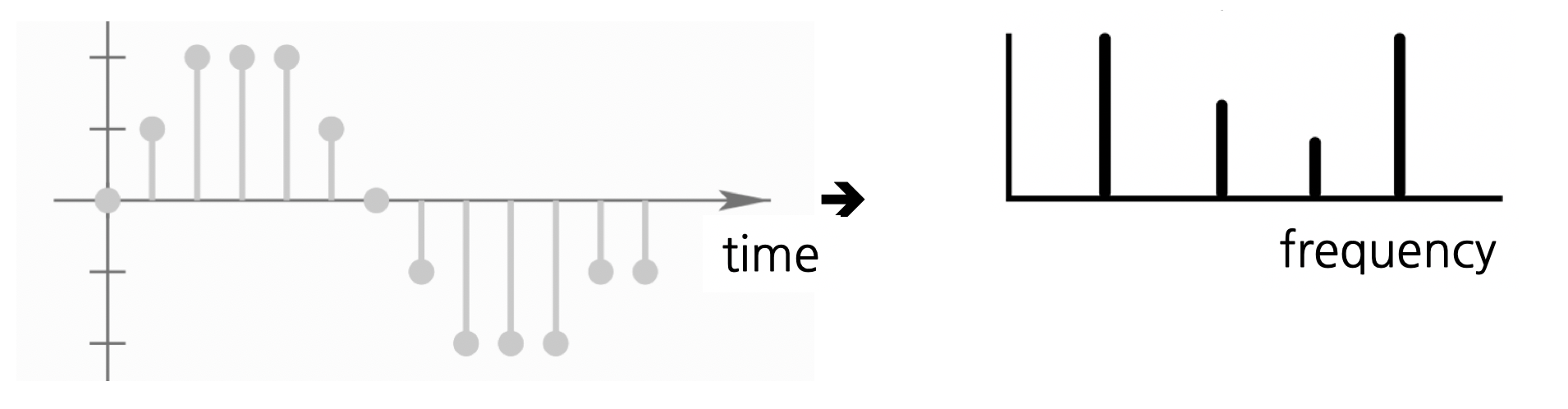
Fast Fourier Transform
개념
![fig04]()
- 푸리에 변환은 시간 도메인의 음성 신호를 주파수 도메인으로 바꾸는 과정을 의미함
- 푸리에 변환을 실제로 적용할 때는
고속 푸리에 변환(Fast Fourier Transform)기법을 쓰는데, 이는 기존 푸리에 변환에서 중복된 계산량을 줄이는 방법임 - numpy의
np.fft.fft함수를 쓰면 쉽게 구현할 수 있음
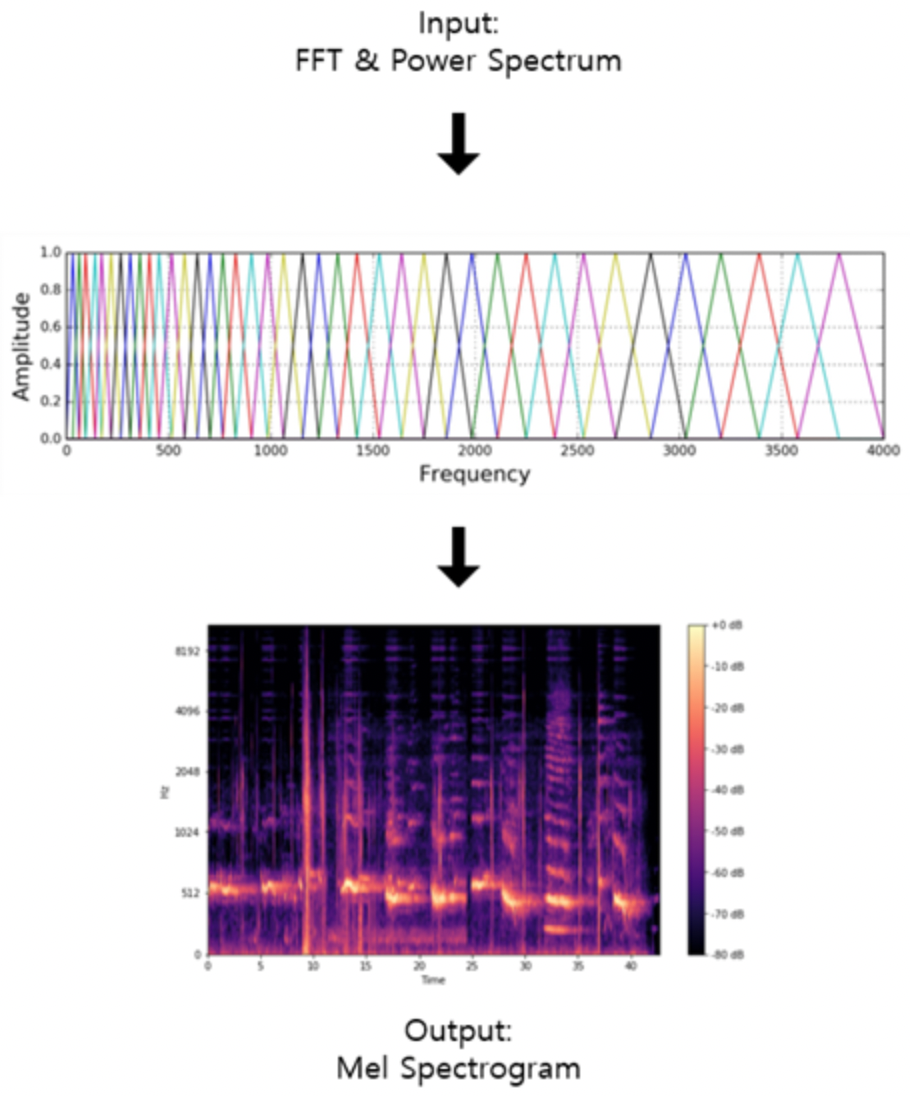
Mel Filter Bank
- 필요성
- 위의 푸리에 변환 과정까지만 적용한다 하여도 충분히 학습 가능한 피처(특징 벡터)를 추출할 수는 있음
- 그러나 사람 몸의 구조를 고려한 Mel-scale을 적용한 피처가 보통 더 나은 성능을 보이기 때문에 이 과정을 진행함
개념
![fig05]()
- 각각의 프레임에 대해 얻어낸 주파수들에 대해서 Mel 값을 얻어내기 위한 filter를 적용함
- 달팽이관의 특성을 고려해서 저주파에서는 작은 삼각형 filter를 만들고, 고주파 대역으로 갈수록 넓은 삼각형 filter를 만듦
- 그래서 위와 같은 삼각형 필터 N개를 모두 적용한 필터를 Mel-filter bank라고 부르며, 이를 통과한 신호는 Mel-spectrogram 피처가 됨
Log-mel Spectrum
- 개념
- 사람의 소리 인식은 로그 스케일에 가깝기 때문에,멜 스펙트로그램에 로그 변환을 수행함
역푸리에 변환으로 만드는 MFCC
- 필요성
- 멜 스펙트로그램 또는 로그 멜 스펙트로그램은 태생적으로 피처 내 변수 간 상관관계가 존재함
- 이는 몇 개의 헤르츠 기준 주파수 영역대 에너지를 한데 모아 보기 때문임
- 이러한 문제는 변수 간 독립을 가정하고 모델링하는 가우시안 믹스처 모델에 악영향을 줌
- 개념
- 로그 멜 스펙트로그램에 역푸리에 변환을 수행하여 변수 간 상관관계를 해소함
03. MFCC vs Mel-Spectrogram
- 단순 비교
- 기존의 컴퓨팅 파워가 부족할 때에는 연산량이 적은 MFCC가 무조건적으로 선호되었음
- 최근에는 학습에 GPU 이용이 가능해짐에 따라 멜 스펙트로그램을 피처로 뽑아서 쓰는 경우도 많고, 실제로 MFCC보다 더 긍정적인 결과를 보인 논문들도 많다고 함
- 하지만 아직 두 피처 중 어느 것이 확실히 좋다라는 것은 없고, 어떤 모델을 쓰느냐에 따라 다를 수 있음
- 어떤 태스크에 어떤 피처를 쓸 것인가?
- 멜 스펙트로그램의 경우 주파수끼리 상관관계가 크기 때문에, 도메인이 한정적인 문제에서 더 좋은 성능을 보임
- MFCC는 decorrelate를 통해서 상관관계를 제거하기 때문에 일반적인 상황에서 더 좋은 성능을 보임
04. 참고 문헌
[1] ratsgo 님의 블로그
[2] sooftware 님의 블로그