이 글은 Mumshad Mannambeth가 강의한 Udemy의 Certified Kubernetes Administrator (CKA) with Practice Tests 강의 커리큘럼을 토대로 공부한 내용을 정리하였음을 밝힙니다.
Drain과 Cordon의 필요성
소프트웨어 업그레이드라든지 패치 적용, 혹은 하드웨어 관리 등 유지보수를 목적으로 클러스터 내의 일부 노드를 중단시켜야 할 때, 쿠버네티스가 어떻게 작동할까?
노드가 중단된 경우의 예시
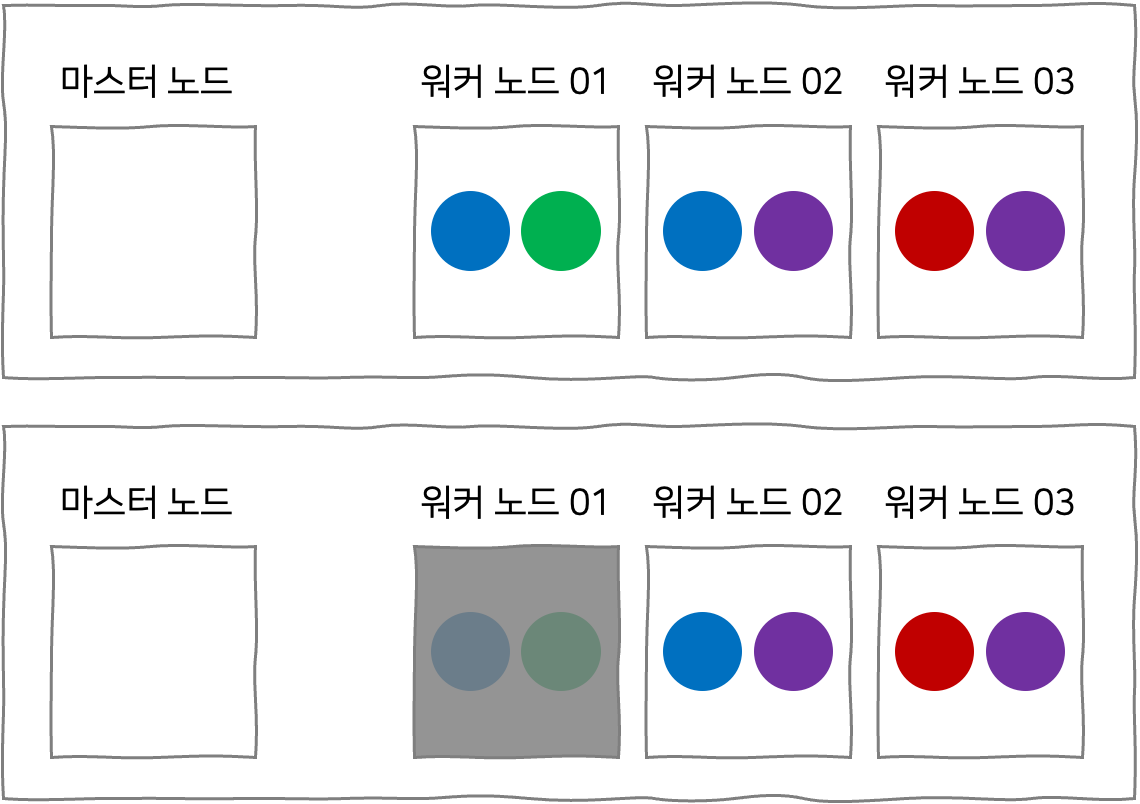
그림 (위)와 같이 마스터 노드와 워커 노드가 구성되어 있으며, 파란색 파드는 레플리카셋에 의해 관리되고 있다고 가정해보자. 그림 (아래)와 같이 어떤 이유에서든 워커 노드 중 하나가 중단되게 되면, 그 워커 노드 내에 있던 파드는 이용할 수 없게 된다.
워커 노드 01이 중단된다 하더라도 파란색 파드의 경우는 다행이 이용할 수 있다. 왜냐하면, 파란색 파드의 레플리카가 다른 워커 노드에도 존재하기 때문에 쿠버네티스가 다른 워커 노드에 있는 파란색 파드를 이용할 수 있도록 스케줄링해주기 때문이다. 한편, 워커 노드 01의 중단으로 인해 다른 노드에 레플리카가 존재하지 않는 초록색 파드는 아예 이용할 수 없게 된다.
이와 같이 노드의 중단 상태가 발생하게 되었다고 하더라도 금방 노드가 살아난다면, kubelet이 다시 작동하게 될 것이고, 순간적으로 멈추었던 파드들도 다시 작동하게 된다. 그런데, 노드의 중단 상태가 5초 이상 지속되면, 노드 내의 파드는 아예 종료가 되고, 쿠버네티스는 해당 노드가 ‘죽었다’고 판단하게 될 것이다. 쿠버네티스에서는 이처럼 파드가 다시 되살아나는지 지켜보기 위해 기다려주는 시간을 pod eviction timeout 이라고 부르고, 컨트롤러 매니저에 기본 값으로 설정된 pod eviction timeout은 5초이다.
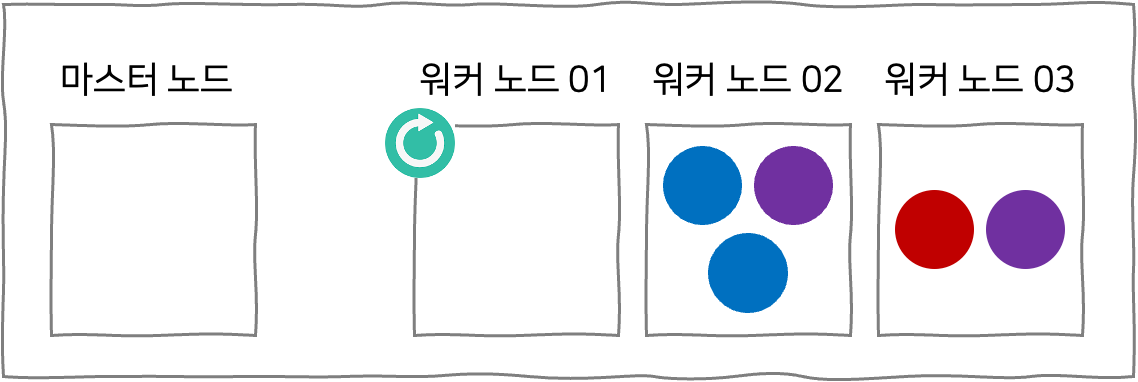
pod eviction timeout이 지나고 나면, 중단되었던 워커 노드 01은 다시 되살아 날 것이다. 이 경우, 레플리카셋에 의해 관리되는 파란색 파드는 워커 노드 01이 중단되었다 하더라도 워커 노드 02에 새롭게 레플리카가 만들어졌을 것이다. 그러나 레플리카셋에 의해 관리되지 않는 초록색 파드의 경우, 워커 노드 01이 다시 되살아난다고 하더라도 노드 중단 시에 사라져버려서 더이상 사용할 수 없게 된다.
위 예제에서 알 수 있듯이, 만약 우리가 pod eviction timeout의 시간 동안 중단되었던 노드가 확실하게 다시 살아날 수 있다는 것을 알거나, 혹은 레플리카셋 덕에 다른 노드에서 파드가 실행될 수 있는 경우에는 재빠르게 노드를 유지보수 한 후 재부팅하여 유지보수를 하면 된다. 그런데 pod eviction timeout 시간 동안 노드가 확실히 다시 살아날 수 있다는 가정은 꽤나 위험한 가정이다.
노드 Drain 하기
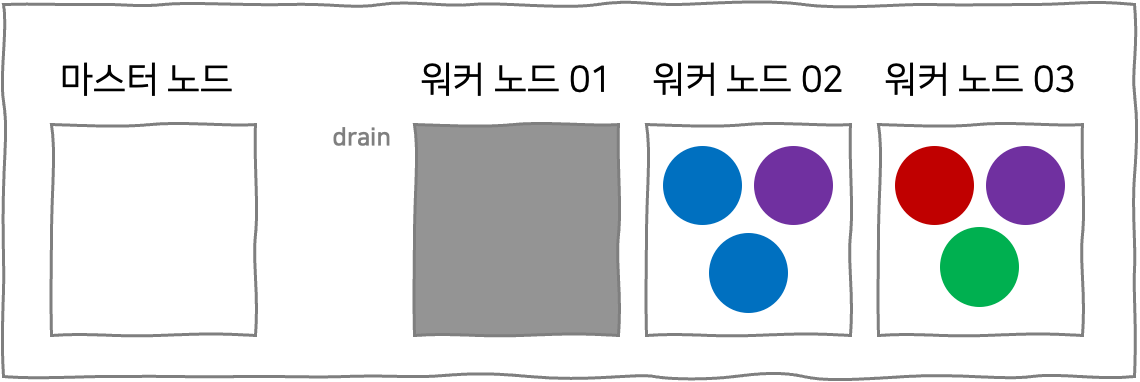
따라서 더욱 안전한 방법으로 업그레이드를 수행할 수 있다. kubectl drain {노드 이름} 명령어를 입력하면, 노드 내의 파드들이 다른 노드로 옮겨지는 것과 같은 효과를 볼 수 있다. 실제로 옮겨지는 것은 아니고, 파드가 실행되던 원래의 노드에서 파드의 컨테이너들이 '우아하게 종료(gracefully terminate)'되며, 다른 노드에서 새롭게 파드가 실행되는 것이다. 공식 도큐먼테이션에는 drain 명령어에 대해 다음과 같이 설명한다.
When
kubectl drainreturns successfully, that indicates that all of the pods have been safely evicted.
Cordon으로 특정 노드에 스케줄링 제한하기
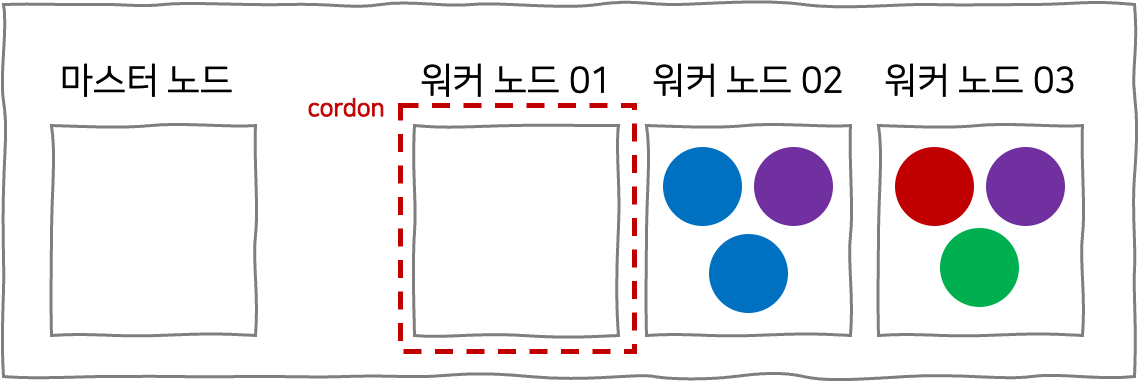
유지보수 하고자하는 노드를 drain 하고 나면, 해당 노드에 대해서 kubectl cordon {노드 이름} 명령으로 cordon 상태를 적용할 수 있다. cordon은 특정 노드를 선택하여 스케줄링 대상에서 제외시키는 방법으로, cordon을 적용한 제한을 uncordon 명령으로 해제하기 전까지는 파드들이 해당 노드에 스케줄링 될 수 없다.
이제 유지보수 하려는 워커 노드 01 내에 있던 파드들이 다른 노드들로 안전하게 옮겨졌으니, 워커 노드 01에 대해 유지보수 할 수 있다. 자유롭게 재부팅해도 상관 없다. 그런데, 유지보수가 완료되고 재부팅한다 하더라도 여전히 cordon 상태이므로, 파드들이 워커 노드 01에는 스케줄링 될 수 없다. kubectl uncordon {노드 이름} 명령어를 통해서 해당 노드에도 스케줄링을 허용해주어야 한다.
참고 문헌
[1] Mumshad Mannambeth의 강의 : Certified Kubernetes Administrator (CKA) with Practice Tests
[2] 시작하세요! 도커/쿠버네티스 (용찬호 지음) : 시작하세요! 도커/쿠버네티스